移动语义
C++11中引入了移动语义也即移动构造函数,主要的目的是避免不必要的拷贝。移动这一概念相对来说比较好理解,因为一个类型的实例是由其成员构成的,构造一个对象实际上就是对对象的成员进行初始化操作。所以移动就可以理解为把一个对象所拥有的成员移动给另一个对象。在Rust这种一开始就表明所有权这一概念的语言中,移动其实将对象成员的所有权转移给另一个对象。
我们知道拷贝构造函数接受的是const引用:
- 为什么用const修饰?因为拷贝这一个行为在语义上蕴含着这一操作不应该修改被拷贝的对象
- 为什么是引用?因为如果不是引用就会导致递归的拷贝构造
class A {
public:
A();
// copy constructor
A(const A& other);
// copy assign operator
A& operator=(const A& obj);
private:
int a;
int *array_;
};
那么移动构造函数应该接受什么作为参数呢?这就必须要引入左值引用和右值引用这组概念了,那么什么是左值?什么是右值呢?
左值、右值
其实用 值(value) 这个词来描述是不准确的,严格来说是表达式,为什么不严格来说呢?我猜可能是约定俗成吧(C++中就是有很多的不严谨的术语,习惯就好)。在C++里面,一个表达式要么是左值,要么是右值。
左值lvalue的这个左是怎么来的呢,主要是相对于赋值运算符=来说的。
lvalue = rvalue
左值顾名思义就是赋值号=左边的值,右值就是右边的值。当然,这种表达是不准确的。
严格来说,左值是在内存中占有一个位置的表达式,换句话说就是,我们可以获得左值的地址。
而右值就是反过来:右值是没法获取其在内存中地址的表达式,当然也就没法修改它(认识到这一点这很重要)。
左值引用、右值引用
右值引用是随着移动语义这个概念在C++11中提出来的,我们都知道引用其实就是一种对某个对象的绑定Binding:
- 左值引用就是只能绑定到左值上的引用,形式上表现为
T& x_lref = x;(假设x已经在之前定义过) - 右值引用就是只能绑定到右值上的引用,形式上表现为
T&& x_rref = T{};
int x = 5;
int& x_lref = x; // ok
int&& x_rref = x; // compile error
int y = 6;
int& product_lref = (x * y); // compile error
int&& product_rref = (x * y); // ok
当考虑到const的时候,情况发生了变化。从语义上看,const就是不可变的意思,而我们在使用非const的左值引用的时候通常就是需要修改这个引用所绑定的对象的时候,所以,const修饰左值引用的时候就是向编译器承诺,我们不会修改这个引用所绑定的对象,这满足右值的语义(右值无法修改),因而const左值引用既可以绑定到左值上,也可以绑定到右值上。
const int& product_const_lref = (x * y); // ok
当左值引用、右值引用和const左值引用作为形参类型的时候也是一样的:
class A {};
void f(A&) {}
void g(const A&) {}
void h(A&&) {}
int main() {
A a;
f(a); // ok
g(a); // ok
h(a); // compile error
f(A{}); // compile error
g(A{}); // ok
h(A{}); // ok
return 0;
}
移动构造函数
了解完右值引用之后我们发现,移动这一语义和右值引用的语义不谋而合(不能修改被移动对象的内容),移动构造函数便可以声明为:
class A {
public:
A();
// copy constructor
A(const A& other);
// copy assign operator
A& operator=(const A& other);
// move constructor
A(A&& other);
// move assign operator
A& operator=(A && other);
private:
int a;
int *array_;
};
移动构造函数做了什么呢?如前所述,移动这一行为就是把被移动对象other的成员转移给当前对象,所以:
- 递归浅拷贝other的每个成员给this的每个成员
- 释放other的所有成员
而移动赋值运算符就是:
- 释放this的每个成员
- 递归浅拷贝other的每个成员给a的每个成员
- 释放other的所有成员
- 返回this指针
以上面的class A为例:
A(A&& other) {
a = other.a;
array_ = other.array_;
other.a = 0;
other.array_ = nullptr;
}
A& operator=(A&& other) {
delete []array_;
a = other.a;
array_ = other.array_;
other.a = 0;
other.array_ = nullptr;
return *this;
}
如果一个类需要拷贝构造函数,那么它一般也需要移动构造函数。反过来,如果一个类需要移动构造函数,但是不一定需要拷贝构造函数。比如std::unique_ptr只允许移动语义而不允许拷贝语义。(更能理解为什么rust里面默认就是移动,而不是拷贝)
因为默认的移动构造函数并不会进行资源的释放,那么对于拥有在堆上成员的类来说,使用移动构造会造成内存泄漏或者重复释放。具体来说,当我们不定义析构函数时会内存泄漏,定义析构函数但不定义移动构造函数时会重复释放。
#include <utility>
class A {
public:
A() = default;
A(int a) : a(a), array(new int[a]) {}
private:
int a;
int *array;
};
int main(int argc, char *argv[]) {
A a{10};
A b{std::move(a)};
return 0;
}
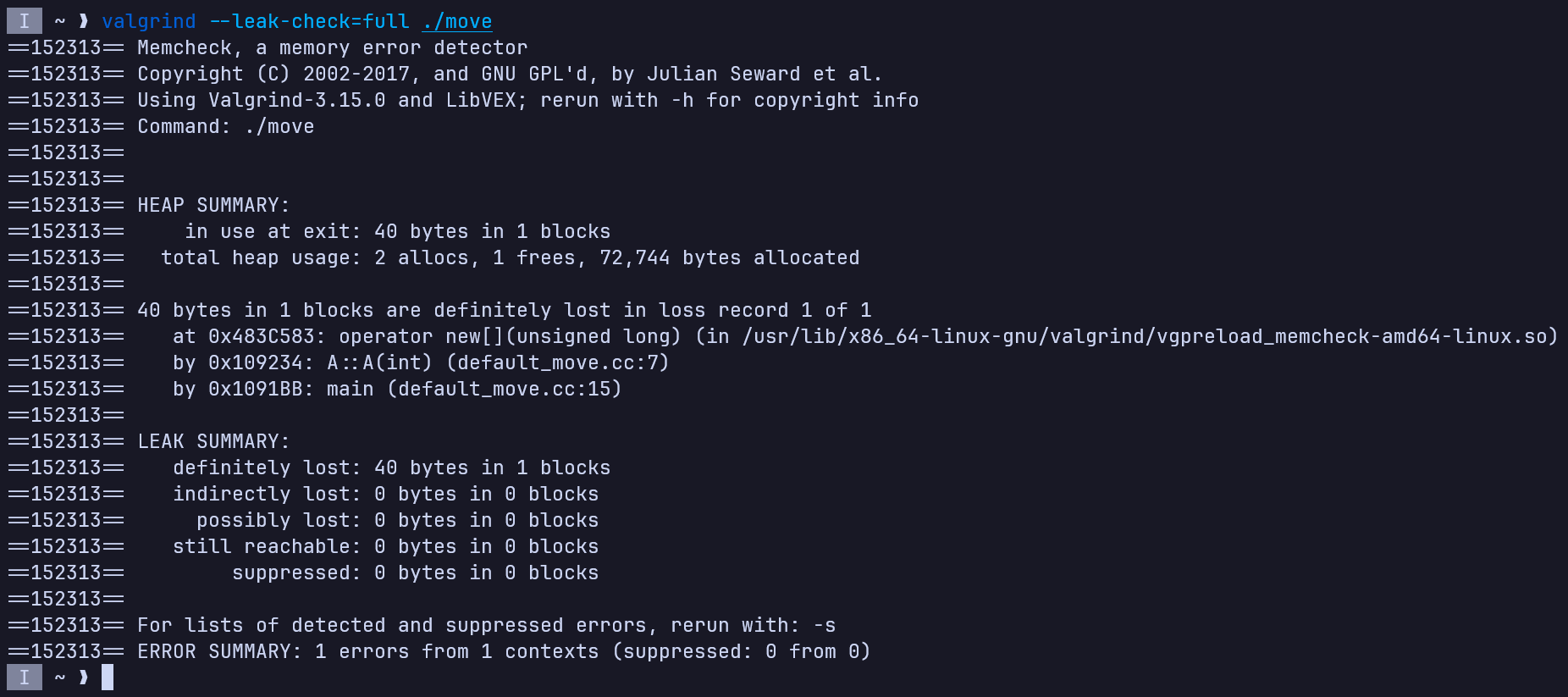
因为默认析构函数不会释放动态分配的内存,所以可以看到泄露了sizeof(int) * 10 = 40Byte的内存。
那加上析构函数之后呢?
#include <utility>
class A {
public:
A() = default;
A(int a) : a(a), array(new int[a]) {}
// destructor
~A() {
delete[] array;
a = 0;
}
private:
int a;
int *array;
};
int main(int argc, char *argv[]) {
A a{10};
A b{std::move(a)};
return 0;
}
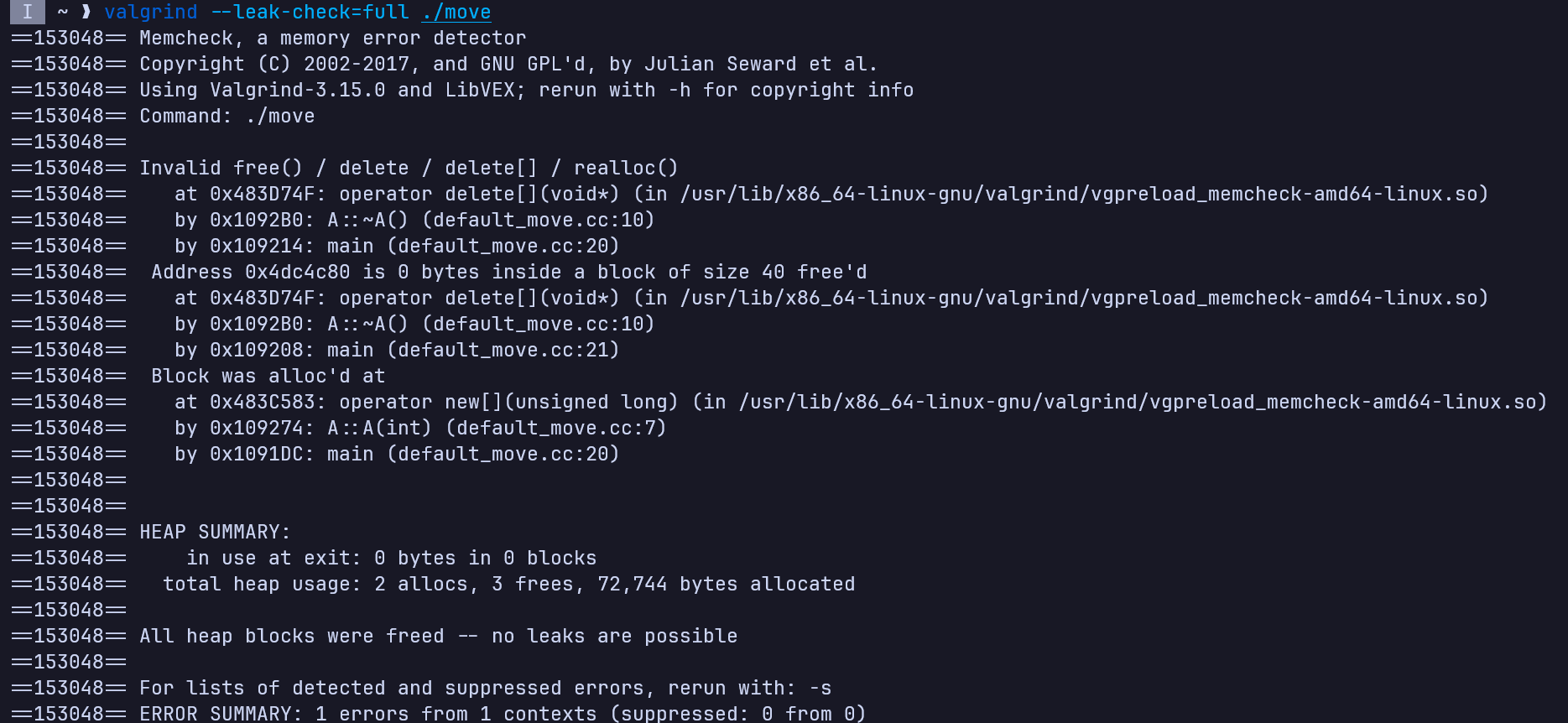
因为默认移动构造函数不会将array置为nullptr,所以当析构两个栈上对象时会对同一块内存重复释放。
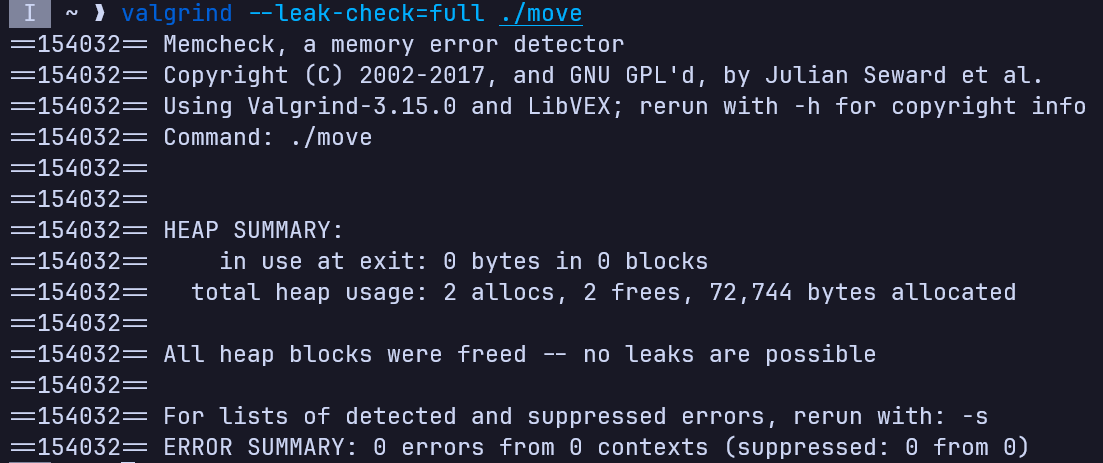
所以正确版本应该是:
#include <utility>
class A {
public:
A() = default;
A(int a) : a(a), array(new int[a]) {}
// move constructor
A(A &&other) {
a = other.a;
array = other.array;
// make other.array to nullptr, avoid re-release
other.array = nullptr;
other.a = 0;
}
// destructor
~A() {
delete[] array;
a = 0;
}
private:
int a;
int *array;
};
int main(int argc, char *argv[]) {
A a{10};
A b{std::move(a)};
return 0;
}
std::move和右值引用
std::move()在<utility>中定义,其作用很简单:就是明确地告诉编译器,需要调用形参是右值引用版本的函数重载
#include <vector>
int main() {
std::vector<A> vec;
vec.push_back(A{}); // rvalue version push_back
A obj;
vec.push_back(obj); // lvalue version push_back
vec.push_back(std::move(obj)); // rvalue version push_back
}
需要使用std::move的原因和移动构造函数存在的意义也是一样的,避免对象成员的重复创建,也就是避免开销较大的深拷贝。
std::forward、引用折叠和万能引用
既然提到了std::move就不能绕过std::forward,它和std::move一样,也是在<utility>中定义,两者都是与引用有关的函数,但是使用场合和作用都不太相同,但是它们各自被使用在了vector的push_back和emplace_back定义中,所以也很有意思,这里做一下对比分析。
因为std::forward和万能引用基本上是绑定在一块出现的,所以首先需要明确万能引用的定义。
万能引用(Universal Reference)就是既可以接受左值、又可以接受右值的引用,还能保持const语义,这也是我们会看到for-range中的变量类型往往是auto&&的原因。
需要特别注意的是:万能引用的概念在类型推导的场合下是才有意义的,具体来说就是在auto, template <typename T>这样的上下文中才有万能引用这个说法。万能引用和右值引用都是使用&&来表示引用的语义,但是只有在类型推导的上下文中,&&表示的才是万能引用。
void f1(int&& t) {} // rvalue reference
template<typename T>
void f1(T&& t) {} // universal reference
int&& v1 = ...; // rvalue reference
auto&& v2 = ...; // universal reference
形参类型是万能引用的函数既能接受左值、又能接受右值,左值和右值对应的实参类型的推导结果不同:
- 传入左值,实参类型被推导为左值引用
- 传入右值,实参类型为推导为非引用类型,也就是值类型
template<typename T>
void f(T&& t) {} // universal reference
struct A {};
A a;
f(a); // T推导为A&
f(A{}); // T推导为A
此时可以看到,如果传入左值,T被推导为A&,模板相当于被实例化为void f(A& && t);,而这样的函数签名在C++中是会报编译错误的,这个时候引用折叠就发挥作用了,引用折叠的规则会将函数最终的签名推导为void f(A& t);,也就是说,当编译器在模板实例化之后生成引用的引用的时候,引用折叠的规则会推导出最终的函数签名,具体如下:
| 形参类型 | 实参类型 | 推导结果 |
|---|---|---|
| A& | & | A& |
| A& | && | A& |
| A&& | & | A& |
| A&& | && | A&& |
std::forward又名完美转发(Perfect Forward),作用其实就是在类型推导的上下文中,可以保持传入实参的引用类型不变,即:传入左值引用就是左值引用,传入右值引用就是右值引用。
#include <iostream>
#include <utility>
template <typename T> void f(T &t) { std::cout << "lvalue\n"; }
template <typename T> void f(T &&t) { std::cout << "rvalue\n"; }
template <typename T> void g1(T &&t) { f(t); }
template <typename T> void g2(T &&t) { f(std::forward<T>(t)); }
struct A {
A(int mem) : mem(mem) {}
int mem;
};
int main() {
f(A{10}); // "rvalue"
g1(A{10}); // "lvalue"
g2(A{10}); // "rvalue"
A a{10};
g2(a); // "lvalue"
return 0;
}
下面是对这4个调用的解释:
- 直接调用
f的右值版本,所以输出"rvalue"; g1接受万能引用,传递一个右值给g1,但是右值的这个属性是在main这个上下文中存在的(A{10}),而对于g1的上下文来说,t就是一个普通的值类型,所以在不使用std::forward的情况下,会调用左值版本的f,从而输出"lvalue";g1接受万能引用,传递一个右值给g2,而在g2中使用了std::forward来保持传入的实参的右值属性,所以会调用右值版本的f,从而输出"rvalue";g2接受左值,并且使用std::forward保持左值的属性,所以调用左值版本的f,从而输出"lvalue";
库代码中的例子
gcc中对于push_back和emplace_back的实现就分别用到了右值引用、万能引用、std::move和std::forward:
// push_back
// 接收左值的重载版本
void push_back(const value_type& __x) {
if (this->_M_impl._M_finish != this->_M_impl._M_end_of_storage) {
_Alloc_traits::construct(this->_M_impl, this->_M_impl._M_finish, __x);
++this->_M_impl._M_finish;
} else
_M_realloc_insert(end(), __x);
}
// 接收右值的重载版本
void push_back(value_type&& __x) { emplace_back(std::move(__x)); }
// emplace_back
// 万能引用,既接收左值又接收右值的唯一版本
template <typename _Tp, typename _Alloc>
template <typename... _Args>
void vector<_Tp, _Alloc>::emplace_back(_Args&&... __args) {
if (this->_M_impl._M_finish != this->_M_impl._M_end_of_storage) {
_Alloc_traits::construct(this->_M_impl, this->_M_impl._M_finish,
std::forward<_Args>(__args)...);
++this->_M_impl._M_finish;
} else
_M_realloc_insert(end(), std::forward<_Args>(__args)...);
}
而两者之间的区别可以看我之前的一篇文章:push_back vs emplace_back