视口预测是什么?
视口预测 (Viewport Predict) 是全景视频中特有的一种用于进一步优化码率自适应的方式。
相较于全景视频 360 度无死角的特性,用户实际上能看到的内容其实只是全景视频中的一个小窗口,这个小窗口就是视口 (Viewport) 。
因为用户在观看全景视频时会在 3DoF 的自由度下转动头部去观看全景视频在空间上的不同部分,所以视口预测做的事情就是在用户的观看过程中预测相较于预测执行时刻的下一时刻的视口位置。
VP 在传输中所处的作用
基于 tile 的全景视频传输方式之所以热门,就是因其可以通过只传输用户 FoV 内的分块而大幅减少观看过程中消耗的带宽。
所以对用户 FoV 的预测是首先要处理的因素,如果 VP 精度很高,那么所有的带宽都可以用很高的码率去传输 FoV 内的分块。
两种方式的基本假设
基于轨迹的方法的基本假设
相对于当前时刻,前 $hw$ (history window)内用户的 FoV 位置对未来可预测的 $pw$ (predict window)内用户的 FoV 位置有影响,比如用户只有很小可能性会在很短的一段单位时间内做 180 度的转弯,而更小角度的调整则更可能发生。
基于内容的方法的基本假设
用户的 FoV 变化是因为对视频内容感兴趣,即 ROI 与 FoV 之间有相关关系,比如在观看篮球比赛这样的全景视频时,用户的 FoV 更可能专注于篮球。
按照提取 ROI 的来源不同可以分为两种类型:
- 从视频内容本身出发,使用 CV 方法去猜测 ROI;
- 从用户观看视频的热图出发,相当于得到了经过统计之后的平均 FoV 分布,以此推测其他用户的 ROI;
基于轨迹的方式是要在最表层的历史和预测的轨迹之间学习,即假设两者之间只有时空关系。
跨用户的方式则假设由用户群体所得出的热图可以用来预测单个用户的 FoV,即利用共性来推断个性。
基于内容的方式直接提取视频显著图来推断 FoV,即进一步假设共性与视频内容本身有关系。
跨用户预测的概念
基本假设
就单个用户而言,在观看视频过程中其 FoV 的变化看似随机,但是其行为可能从用户群体的角度去看是跨用户相通的,即多个用户在观看视频时可能会表现出相似的,可以学习的行为模式,这种行为模式可以帮助提高 VP 的精度。
实际应用
基于轨迹的跨用户:如果训练的模型是基于轨迹的离线模型如 LSTM,那么实际上训练好的模型已经学习到了这种跨用户的行为模式;而如果采用的是边训练边预测的模型如 LR(输入历史窗口的经纬度数据,输出预测窗口的经纬度数据),那么这样的模型就是纯粹的单用户模型。
基于内容的跨用户:将用户在观看视频帧时的注意点作为研究对象,找到用户群体在面对同一帧视频时共同关注的空间区域,而这就是用户间相似的行为模式。这种与内容相结合的跨用户方式即为实际研究中所指的跨用户的研究方式。(实际上就是基于内容的研究方法,只不过出发点不是视频本身,而是用户在观看视频时的 FoV)
实际应用
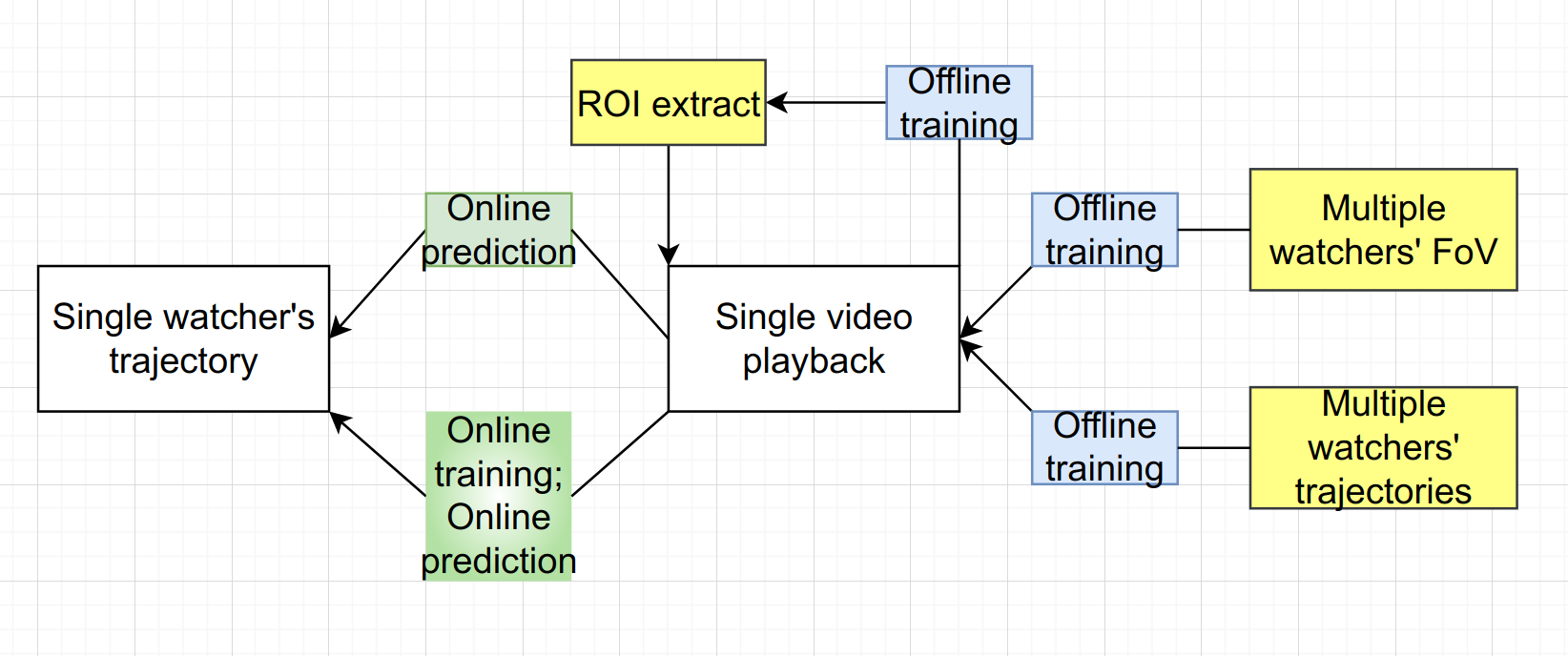
图中 3 个黄色矩形表示 3 种方法:
ROI extract:基于内容的预测
Multiple watchers’ FoV:跨用户的预测
Multiple watchers’ trajectories:基于轨迹的预测
绿色渐变矩形表示直接使用用户当前的历史轨迹数据去训练模型,接着做出预测。
研究方法
基于轨迹的方法
在线训练:输入历史窗口的位置信息,不断迭代修正模型,输出预测窗口的位置信息。
离线训练:输入任何采样条件下的多对 hw 和 pw 信息来拟合模型。
跨用户的方法
求出多个用户在同一帧上的热图,以此作为 FoV 预测的依据。
基于内容的方法
提取视频帧中的显著图,以此作为 FoV 预测的依据。
优点
- 使用回归实现的在线训练模型实现简单,反应迅速,有优秀的短期预测精度。
- 因为独立于 $pw$ ,并且不需要历史窗口 $hw$ 的轨迹输入,跨用户的热图可以帮助长期的预测,可以提供合理的离线全视频 FOV 预测,并具有一致的性能。
- 显著图对于 ROI 集中突出的预测效果较好。
缺点
- 使用回归实现的在线训练模型在预测窗口增大时,性能会显著下降。
- 提取显著图的方式一方面训练开销比较大,另一方面对于 ROI 不够集中突出的视频效果并不好。