进程
是什么
学操作系统课的时候学过一句话叫做:进程是操作系统资源分配的最小单位,进程的资源直接由 OS 分配,并存储在进程控制块 PCB 中:
- 进程标识符 PID
- 进程状态:就绪、运行、阻塞
- 内存资源:
- 代码段、数据段、堆和栈
- 文件描述符 fd :
- stdin、stdout、stderr、以及进程打开的文件描述符列表比如本地文件以及网络连接等的 fd
- 寄存器:
- PC、SP、还有其他的通用寄存器
- 进程控制信息:
- 父进程 ID ,子进程 ID ,以及信号处理器这些
有什么用
在拿进程和程序做对比的时候我们知道,进程就是运行着的程序(这里的运行指的是程序被加载到内存空间中然后开始按照程序指令执行,而不是指进程状态中的运行状态),受 OS 的调度,可以说我们写程序的目的就是要让 CPU 可以按照磁盘上的代码指令来执行操作,进程就是实现这一目的的过程。
因为 OS 使用了虚拟内存这一概念,使得每个进程都认为自己是独占 OS 的,所以一个进程是不知道其他进程的存在的。因而如果面对需要多个进程协作完成一项任务的时候(其实这种情况的描述从逻辑上应该是自上到下的,先有的是一项任务,我们通过分析发现这两个任务需要写多个程序来完成),就会不可避免地引入进程间通信 IPC 。
常用的进程间通信手段大概有 6 种:消息队列、共享内存、匿名管道、命名管道、信号量、Socket,这几种方式根据需求的不同都有自己的用武之地,不过我个人最习惯用的还是 Socket ,因为它具有最优的可扩展性(跨主机、跨语言),可记录性(可以使用 tcpdump/wireshark 抓包),也完美符合我对于通信这一名词想象(明确的通信双方、全双工的信道)。
从我的实际项目经历中来看,我的 Unity 客户端实例需要把游戏运行过程中产生的 2D 轨迹数据输入给 Python 端的 AI 模型,并获取模型输出。对于这一场景,我的首选就是 Socket 通信,首先是因为 Socket 具备全双工的特性可以满足需求,其次是使用 Socket 可以在 AI 模型部署到其他主机上的时候也能正常运行。
线程
是什么
上面说到进程是 OS 资源分配的最小单位,这句话的下半句是:线程是操作系统调度的最小单位,这句话其实暗示了,线程和进程的概念对于单线程的进程而言是相同的。
OS 在调度 CPU 的时候是以线程为单位的,也就说明线程其实也是一种 OS 级别的概念。对于 Linux 而言,线程和进程使用的是相同的数据结构 task_struct 来表示的,不过进程的创建使用的是 fork() 这一系统调用,而线程的创建用的是 clone() 这一系统调用。
结合前半句话,说明 OS 在分配资源的时候分配不到线程这个层面上(单线程进程是特例),对于同一个进程的多个线程,他们之间共享进程的代码段、数据段和 fd 这些,不过每个线程都拥有自己独立的堆、栈空间。
有什么用
因为每个进程都会拥有上面列出的这些资源,直接受到 OS 的控制,所以进程的创建和销毁不可避免地会涉及到相对比较大的时间开销。
相比之下,线程因为可以直接继承并共享进程的部分资源,所以线程的创建和销毁要更加轻量。
也正因如此,同一进程之间的多个线程之间只需要使用一些编程上的技法就可以完成通信,常用的就是各种锁、条件变量以及阻塞队列。
什么时候用多线程
首先需要考虑的是能不能使用多线程。多线程的执行过程是 OS 调度 CPU 的多个核心来分别执行多个线程的过程,因而最适合使用多线程的任务一定具备:划分给各个线程之间的任务没有重叠、也无需通信(或者说没有依赖关系)的特性,每个任务都是 Compute-Intensive 的。
从我的实际项目经历中来看,在把 GPU 显存中的 yuv 图像数据回读到内存中的时候,图像的不同部分之间是相互独立的,因而这个过程天然适合使用多线程来完成,主线程只需要等待多个线程读完数据之后执行下一步操作即可。
其次需要考虑的是多线程能带来多大的收益。单线程和多线程的区别其实就是可以占有并利用的 CPU 核心数的区别,因此当任务的瓶颈不在于 CPU 的时候就需要考虑是否有使用多线程的必要。根据 Amdahl’s law ,$S(n)=\frac{1}{(1-P)+\frac{P}{n}}$,当处理单元数趋向于无穷的时候,并行化所带来的加速比 $S(n)$ 将趋近于 $\frac{1}{1-P}$ 。如果任务中可并行的部分比较小的情况下,可能就没有并行化的必要了。
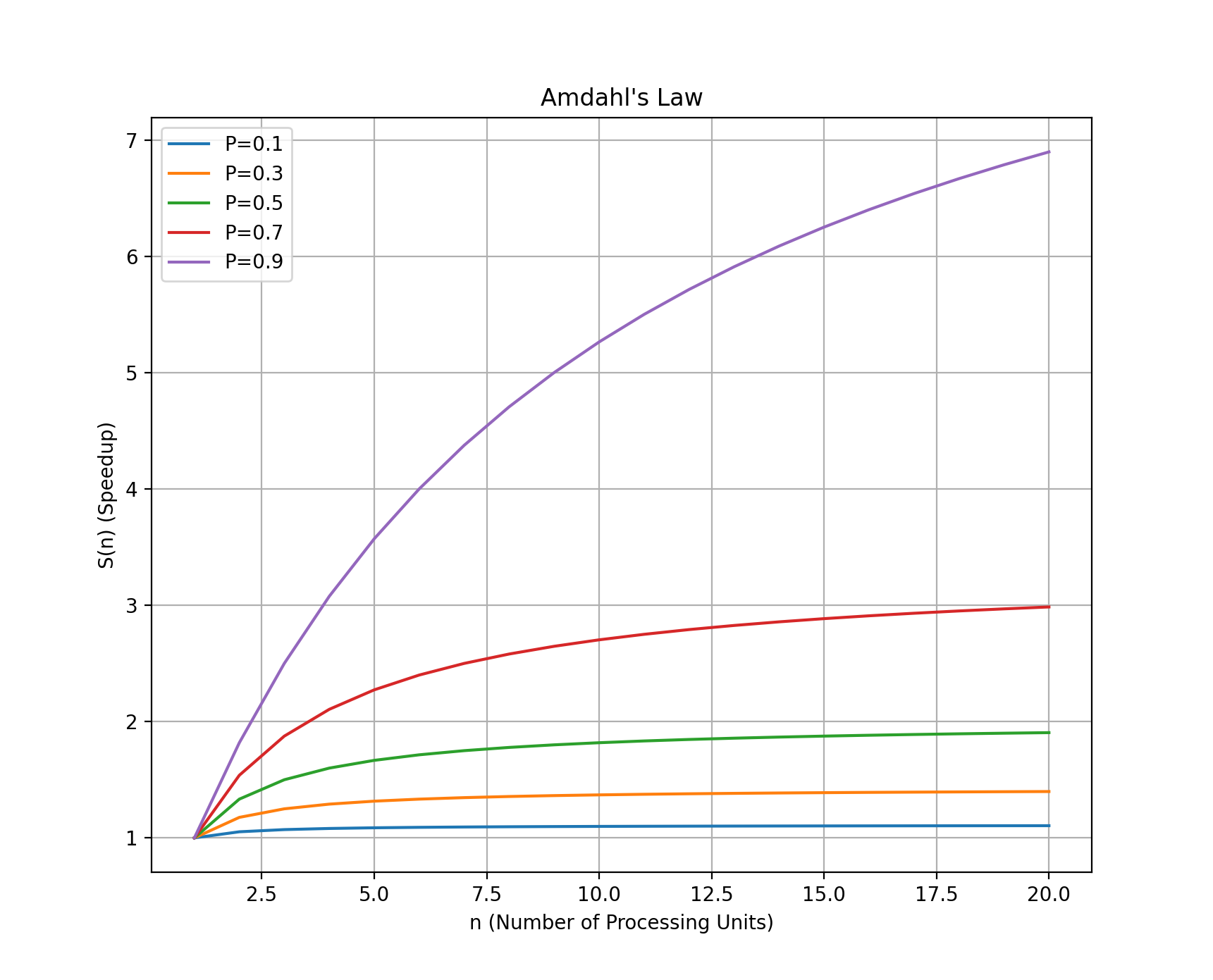
实际任务中使用的线程数量应该结合可以利用的系统资源(CPU 和内存)和相应任务的性能瓶颈两方面考虑,这里之所以要强调是可以利用的资源是因为我们需要从 OS 的角度来考虑,如果当前进程使用了 CPU 的全部核心,那么 OS 上的其他任务就不能得到及时响应,当然因为线程本身需要独立的堆栈空间,所以线程的理论上限需要考虑内存大小。另一方面,多线程本质上只是在提高当前任务对于 CPU 的使用率,但是一个任务的执行不可能只用到 CPU ,还会用到内存以及可能涉及 IO 操作。就算是不涉及锁的并行读操作,也需要考虑 IO 可以利用的总线带宽大小,所以对于这样的任务使用多线程并行化带来的性能提升曲线应该会随着线程数的增多而呈现先升后降的趋势。还是以我上面遇到的问题为例,从 GPU 显存回读数据到内存中的操作就会受到 PCIe 总线带宽的限制,如果线程数过多就会造成多个线程对于总线的争用,这样就会导致性能下降。
怎么用多线程
默认的多线程使用方式就是在需要多线程执行任务的时候创建线程,在任务执行完毕之后销毁线程(就是直接交给 OS 来进行线程的创建和销毁)。
而实际上,我们常用的是线程池的方式,也就是在任务开始的时候我们就创建多个线程并且保存在一个线程池中,通过任务队列的形式确定将那个任务分配给哪个线程。这样做的方式其实就是把对线程的控制权从 OS 转移到程序员,避免了重复的线程创建和销毁带来的开销。
下面是使用 C++ 实现的一个简单的线程池:
#include <condition_variable>
#include <functional>
#include <iostream>
#include <mutex>
#include <queue>
#include <thread>
#include <vector>
class Task {
public:
Task(std::function<void()> f) : func(f) {}
void operator()() const { func(); }
private:
std::function<void()> func;
};
class ThreadPool {
public:
ThreadPool(size_t numThreads) : stop(false) {
for (size_t i = 0; i < numThreads; ++i) {
workers.emplace_back([this] {
for (;;) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(queueMutex);
condition.wait(lock, [this] { return stop || !tasks.empty(); });
if (stop && tasks.empty())
return;
task = std::move(tasks.front());
tasks.pop();
}
task();
}
});
}
}
template <class F> void enqueue(F &&f) {
{
std::unique_lock<std::mutex> lock(queueMutex);
tasks.emplace(std::forward<F>(f));
}
condition.notify_one();
}
~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queueMutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers) {
worker.join();
}
}
private:
std::vector<std::thread> workers;
std::queue<Task> tasks;
std::mutex queueMutex;
std::condition_variable condition;
bool stop;
};
// 示例任务函数
void printHello(int num) {
std::cout << "Hello from thread " << num << std::endl;
}
int main() {
ThreadPool pool(4); // 创建线程池,包含4个线程
// 向线程池添加任务
for (int i = 0; i < 8; ++i) {
pool.enqueue([i] { printHello(i); });
}
return 0;
}
协程
是什么
协程这一概念可以理解为“函数plus”,普通的函数只有两种行为:调用(Invoke)和返回(Return)。协程比函数多了两种行为:挂起(Yield)和恢复(Resume)。在只使用函数的情况下,程序的执行流可以只用一个栈就能模拟(调用函数时 push ,函数返回时 pop ),而引入协程之后,因为其具有挂起这一行为,所以需要额外的空间(比如堆)来暂存协程的上下文。
有什么用
协程的作用可以用一句话来描述,即:协程就是用单线程的方式完成并发的任务逻辑。
协程其实与进程和线程没有太近的“亲缘关系”,只是在作用上有着相近的效果,即宏观上看是并发执行的。以经典的生产者-消费者任务为例:
- 多进程/多线程:至少需要一个生产者进程/线程,消费者进程/线程,两者之间可能需要使用一个单向管道作为数据缓冲区来提高性能(或者说控制管道大小来实现不同的任务逻辑)。
- 协程:只需要一个线程,通过两个分别负责生产和消费的协程来完成,即:生产者协程生产一定数量之后挂起,并调用消费者协程。消费者协程消费完之后挂起,并调用生产者协程,如此交替往复进行。
协程相比于上面提到的进程和线程,区别在于协程是运行在用户态的,或者说协程的控制权是掌握在程序员手中的,由程序员负责控制在什么时候把 CPU 的使用权交给哪个协程。
什么时候用协程
协程的使用情形其实很简单,即:你需要以同步且并发的方式来完成任务的时候就是使用协程的时候。协程从根本上来讲就是同步且阻塞的,程序员决定什么时候把CPU的使用权交给哪个协程,而多线程的调度是受OS内核调度的,其触发点来自于不可预见的硬件时钟中断,要想实现同步调用就必须使用锁/条件变量这种技术来确保线程安全(不论多个线程以什么次序被调用完成任务时的结果都应该是一致的),所以加重了程序员的心智负担和代码的维护成本。
协程类型
协程根据存储运行上下文的方式主要分为:有栈协程和无栈协程。首先需要声明这里的“栈”指的不是函数的调用栈的意思,因为对于大多数语言来说,一个函数调用另一个函数时总是需要调用栈的。这里说的栈指的是用来保存协程运行状态的额外空间。有栈和无栈的区别不是说需不需要额外空间(不可能不需要),而是说协程有没有独属于自己的用来保存运行上下文的额外空间。感慨一句,计算机学科的很多人就是喜欢发明一些概念,而且还喜欢用一些比较耳熟能详的简略的词来描述它们,让人在理解的时候不得不去做概念辨析。
有栈协程
前面说过,协程因为比函数多了yield和resume两种状态,所以正常来说就需要一个额外的空间来保存协程在yield执行之前的上下文,不然当CPU使用权再次交给这个协程的时候,怎么能从上一次协程让出CPU的地方继续执行呢?有栈协程就是这种提供额外空间来保存运行上下文的协程。有栈协程的主要代表是goroutine,也就是说,当用go关键词修饰一个函数的时候,这个函数就变成了一个有栈协程。这个额外空间的大小是个典型的优化问题,分多了浪费,分少了溢出,go runtime实现了一个协程栈扩容的机制来解决这个问题。
无栈协程
无栈协程不利用额外空间能完成协程的任务吗?答案当然是不能,没有额外空间怎么确定上下文呢?那这里的无栈是什么意思呢?其实就是说,这个协程没有属于自己的、独立的额外空间来存储上下文,其上下文信息需要保存在另外一个地方,协程的挂起和恢复过程的本质就是:由协程不同挂起点组成的状态机的状态转移过程。
无栈协程的典型关键字就是async/await,在C#/Rust/JavaScript中都是用的它们,底层原理都是编译器/解释器基于关键字的声明位置生成一个专属于这个协程的状态机。从下面的一个示例实现可以看出无栈协程的本质:
// 协程的结构
void fn() {
int a, b, c;
a = b + c;
yield();
b = a + c;
yield();
c = a + b;
}
// 无栈协程其实就是这么实现的
class fn {
int a, b, c;
int state_ = 0;
void resume() {
switch(state_) {
case 0:
return fn1();
case 1:
return fn2();
case 2:
return fn3();
}
}
void fn1() {
a = b + c;
}
void fn2() {
b = a + c;
}
void fn3() {
c = a + b;
}
};
无栈协程相比于有栈协程最大的不自由的点在于:不能在非async的上下文中使用await,因为无栈协程的状态需要保存在async的上下文中,而有栈协程则可以在任意嵌套的位置进行挂起操作。比如在JavaScript中:
async function fn(array) {
array.forEach(ele => {
// Uncaught SyntaxError:
// await is only valid in async function
let res = await handleEle(ele)
})
}
怎么用
目前 C++ 的协程只是在 C++20 中提供了机制,标准库的实现可能会在下一个版本 C++23 中提供,不过最新版本的g++做了支持:
#include <iostream>
#include <thread>
#include <coroutine>
#include <future>
#include <chrono>
#include <functional>
struct Result{
struct promise_type {
Result get_return_object() { return {}; }
std::suspend_never initial_suspend() { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void return_void() {}
void unhandled_exception() {}
};
};
std::coroutine_handle<> coroutine_handle;
struct AWaitableObject
{
AWaitableObject() {}
bool await_ready() const {return false;}
int await_resume() { return 0; }
void await_suspend(std::coroutine_handle<> handle){
coroutine_handle = handle;
}
};
Result CoroutineFunction()
{
std::cout<<"start coroutine\n";
int ret = co_await AWaitableObject();
std::cout<<"finish coroutine\n";
}
int main()
{
std::cout<<"start \n";
auto coro = CoroutineFunction();
std::cout<<"coroutine co_await\n";
coroutine_handle.resume();
return 0;
}
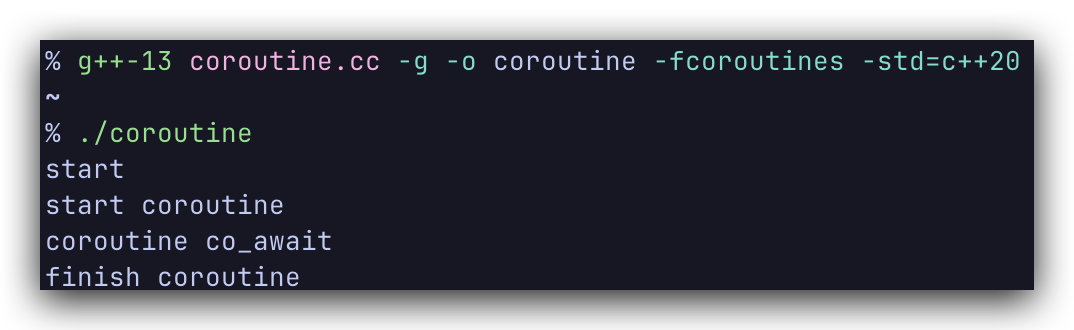
使用最新版本的g++编译运行:如果是macOS需要把g++改成g++-13
g++ coroutine.cc -g -o coroutine -fcoroutines -std=c++20
总结
从进程到线程再到协程的概念,其使用层级是逐级向上的。
- 如果希望程序可以充分利用多核资源来实现 CPU 密集型操作的并行加速,那可以使用多线程,通过使用锁/条件变量等方式来完成线程之间的协作。
- 如果不满 OS 的任务/线程调度策略,那可以在程序中使用并调度协程,用单线程+协程挂起和恢复的逻辑来完成宏观上的并发操作。