论文概况
Link:Content Assisted Viewport Prediction for Panoramic Video Streaming
Level:IEEE CVPR 2019 CV4ARVR
Keywords:Trajectory-based predict,Content-based predict,Multi-modality fusion
主要工作
基于轨迹预测
输入:历史窗口轨迹
模型:64 个神经元的单层 LSTM,在输入层后面加上一个额外的减法层进行点归一化,以及一个加法层来恢复输出之前的值;用 ADAM 进行优化,MAE 作为损失函数。
跨用户热图
除了观看者自己的历史 FOV 轨迹之外,其他观看者对同一视频帧的观看方向也有启发性。
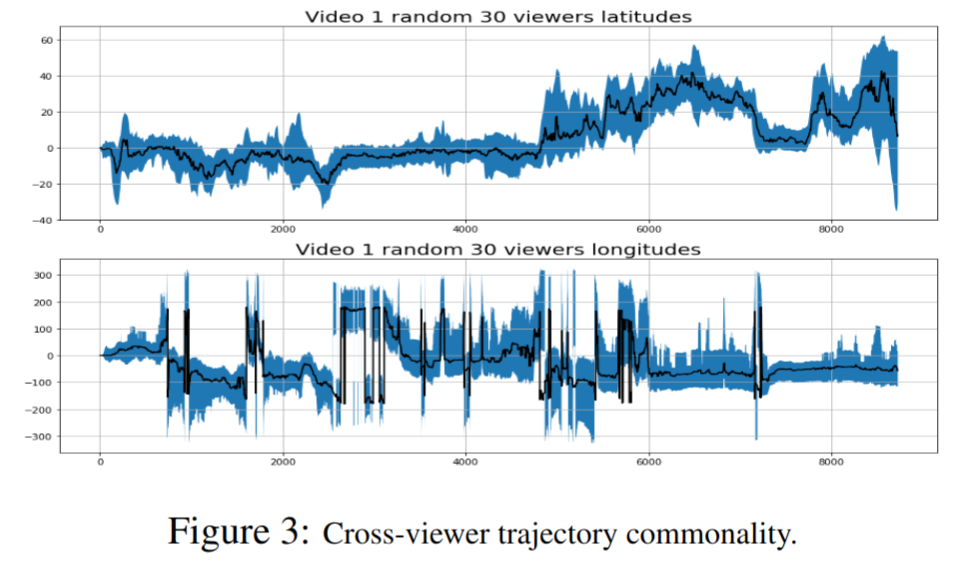
对视频的每一帧,首先收集用户的观看方向(坐标使用原始的来自三个方向的欧拉角表示,而非经纬度)。
接着将坐标投影到用经纬度表示的 180x360 像素的平面图上,对于图中的每个像素点,可以数出其被看到的次数;并对周围像素应用二维高斯光滑。
上面的过程可以为视频生成热图:
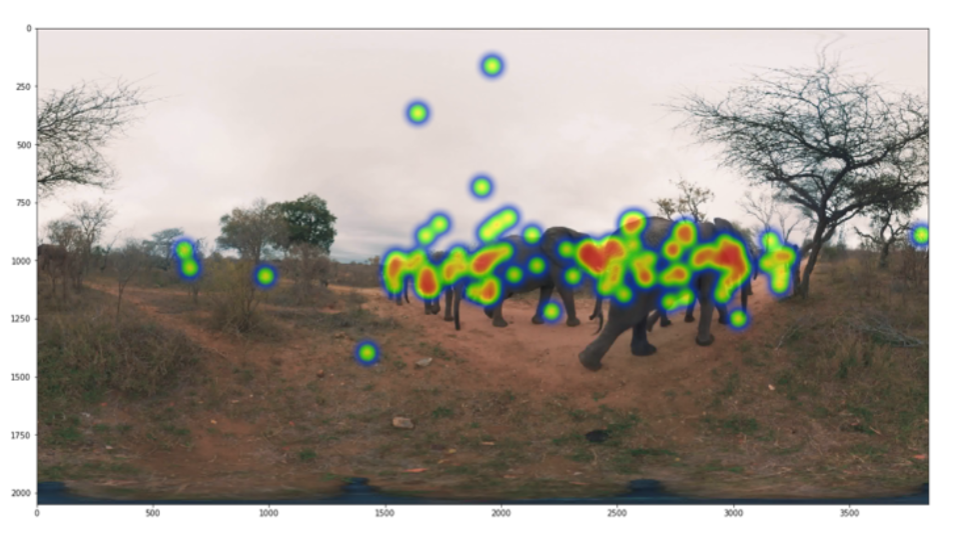
视频帧的显著图
鉴于观看相同的全景视频时跨用户行为的共性,进一步假设是内容促使多个观众观看公共区域,因此提取出每个帧的显著图可能会表明用户的 RoI。
对特定的视频帧,应用经典的特征密集型方法——Ittykoch,它首先根据强度、边缘、颜色和方向将图像分解为多个特征通道,然后将它们组合成识别显著区域。
除了在静态视频帧上检测显著性之外,进一步进行背景减法来减少不太可能感兴趣的区域:应用基于高斯混合的背景/前景分割算法,高级思想是在连续帧之间临时过滤变化的像素点。
结合上面这两个过程可以为视频帧提取时间显著图。

多模态融合
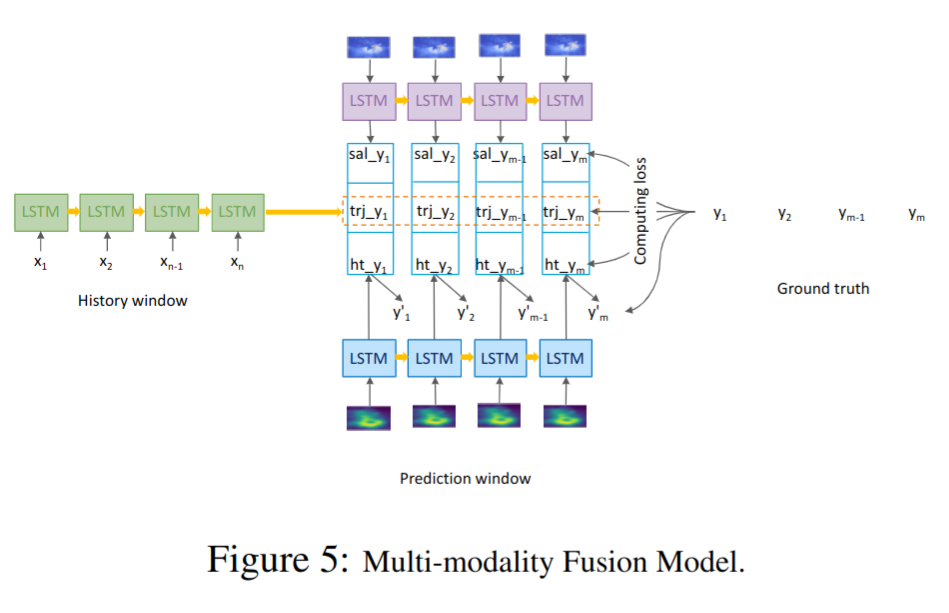
使用包含 3 个 LSTM 分支的深度学习模型来融合上述的几种预测方式的结果。
基于轨迹的 LSTM(图中绿色分支)从历史窗口 $hw$ 中接受 $n$ 个坐标的输入,接着预测未来窗口 $pw$ 中的 $m$ 个坐标,用 $trj_y_{i}$ 表示;
基于热图的 LSTM(图中蓝色分支)将每个预测步骤对应的视频帧的热图作为输入,并在 $pw$ 中输出第 2 组 $m$ 个坐标的预测,用 $ht_y_{i}$ 表示:
对于每个热图,让其通过 3 个卷积层,每个卷积层后面都有一个最大池化层。然后,在此图像特征提取之后,应用展平步骤和 1 个密集层来回归坐标(经纬度表示)。
基于显著图的 LSTM 采用与热图相似的架构,将显著图作为输入,在 $pw$ 中输出第 3 组 $m$ 个坐标的预测,用 $sal_y_{i}$ 表示。
对热图和显著图的分支,应用 TimeDistributed层,以便其参数在预测步骤中保持一致。
最终在每个预测步骤连接 $trj_y$ , $ht_y$,和 $sal_y$ ,并产生一个最终输出 $y$ 。
每个模型的损失函数采用 MAE,优化函数采用 ADAM。
为每个分支的输出以及最终的输出都检查损失,单独和联合地去调整其参数。
评估
使用 2 折的交叉验证。
超参数
- $pw$ 的大小:0.1s,1.0s,2.0s;
- $hw$ 的大小:0.05s,0.6s,1.0s;(分别与上面的 $pw$ 对应)
- 用于训练的用户数:[3, 10, 30]
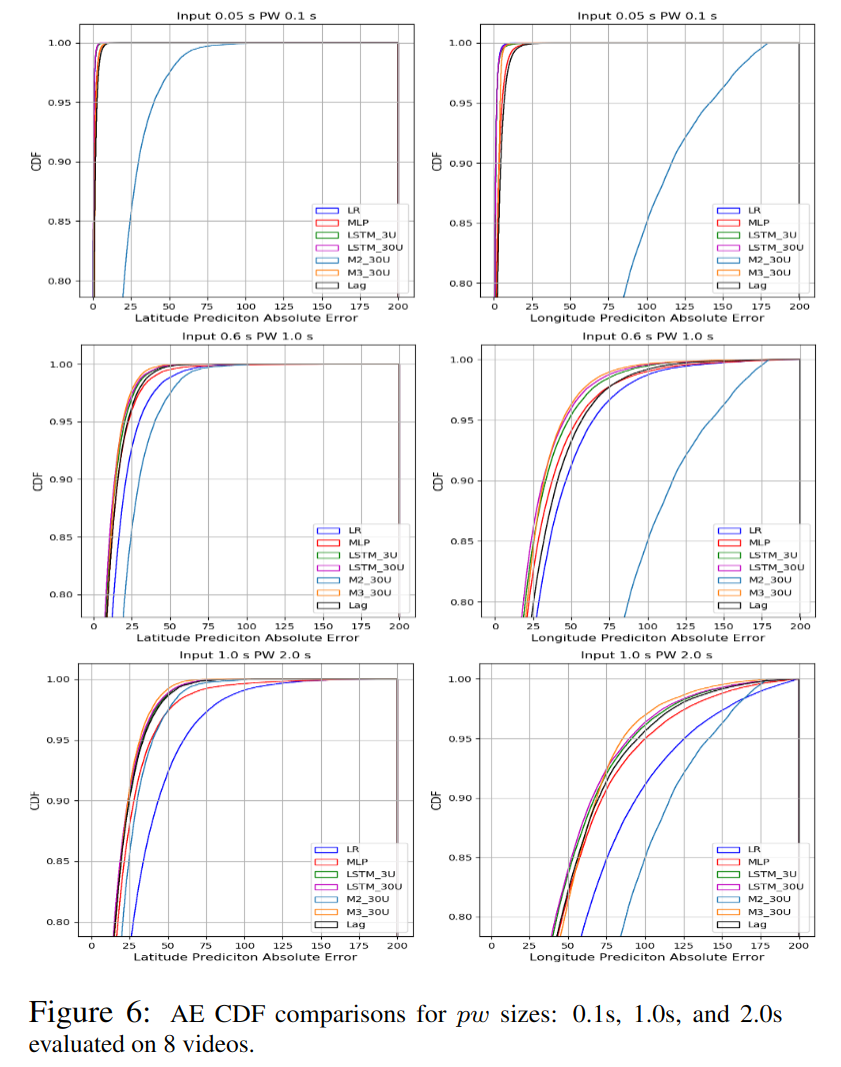
结果与分析
- 所有模型的预测精度随着 $pw$ 的增长而下降,表明长期预测问题更难解决;
- 所有模型的精度预测误差几乎是纬度预测误差的二倍,可能由于运动区域在水平方向的翻倍;
- 线性回归模型只有在 $pw$ 很短的时候预测精确,随着 $pw$ 的增长,其预测精度会迅速下降;
- 基于 LSTM 的轨迹模型始终优于所有 $pw$ 的基线模型,但更多的训练观众无助于显着提高准确性。
- 跨用户的热图和显著图可以帮助长期的预测,可以提供合理的离线全视频 FOV 预测,并具有一致的性能(因为独立于 $pw$ ,并且不需要历史窗口 $hw$ 的轨迹输入),当 $pw$ 增长时,其预测精度超过了基于历史轨迹的模型;
- 结合 3 种模型之后,可以平衡来自历史轨迹、跨用户兴趣和内容显著性的输入,不论 $pw$ 长或短都能产生优化的预测结果;
例外情况
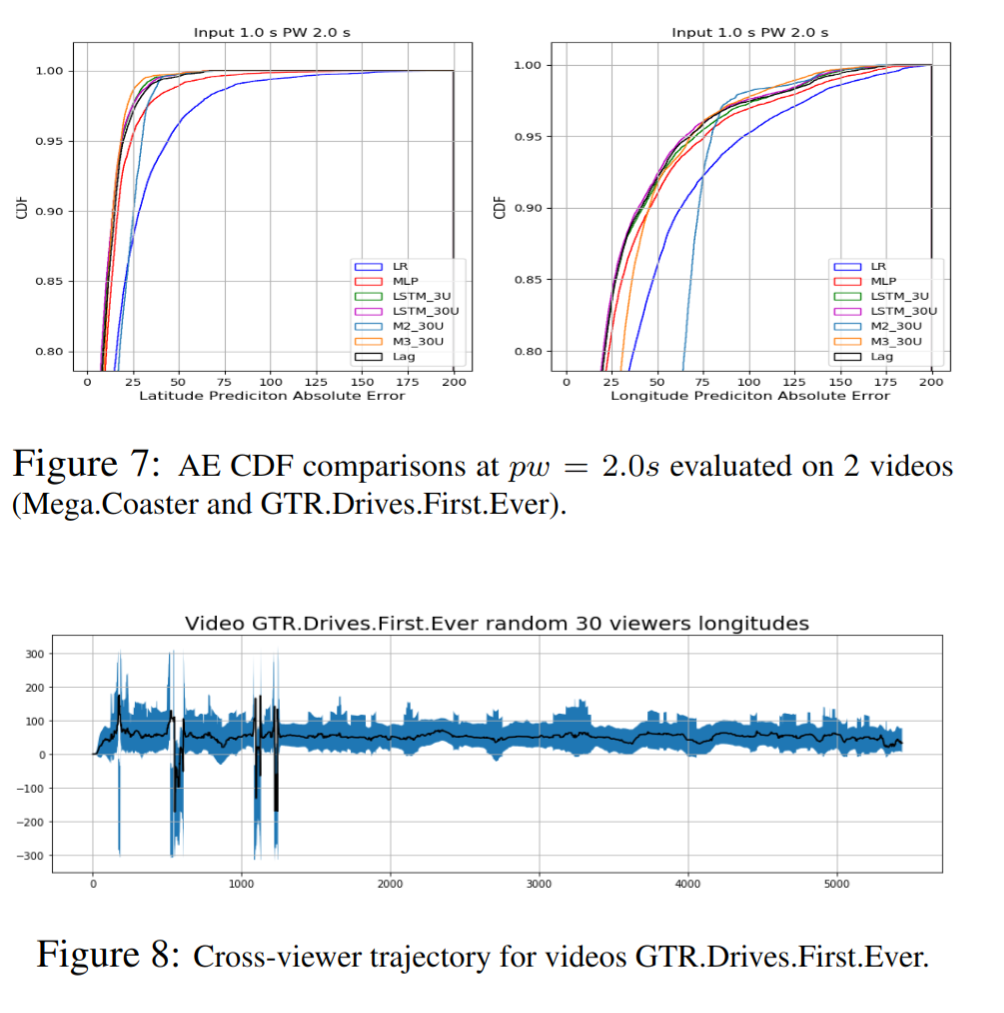
M3 在经度上的表现并不适用于上面图中标示的两个视频(Mega.Coaster 和 GTR.Drives.First.Ever)
原因分析:
这两个视频的共同特点是在驾驶路径的一侧具有高运动内容的驾驶内容,因此用户在观看这些视频时,大多数 FOV 始终以行驶轨迹为中心。因此用户不太可能改变其观看方向,这导致即使 $pw = 2.0s$ 时,单一基于轨迹的模型的预测精度也更高。相比之下,从对内容角度出发的分析无济于事,但可能会引入观众可能会忽略的变道,进而造成预测误差。