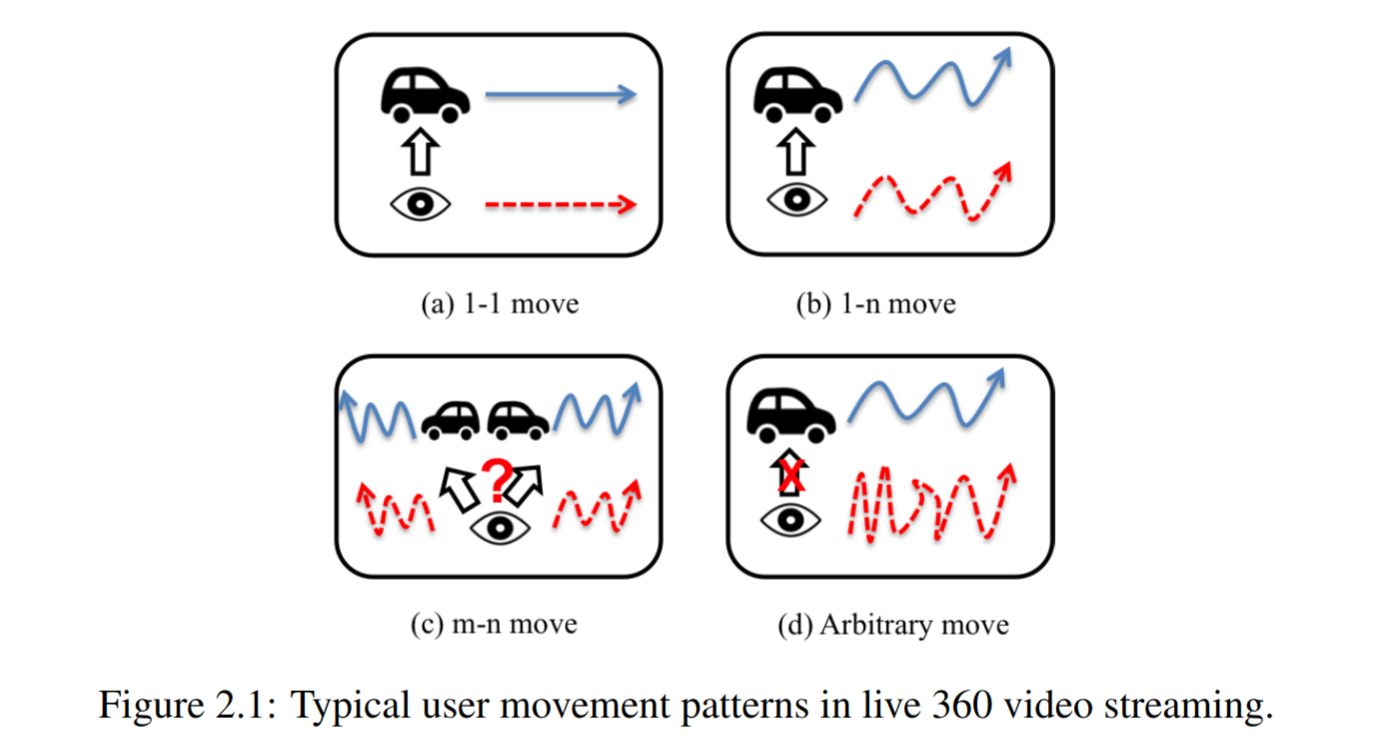
LiveMotion
Motivation
基于视频中物体的运动模式来做对应的FoV预测。
将用户的FoV轨迹与视频内容中运动物体的轨迹结合到一起考虑:
细节可以参见:note-for-content-motion-viewport-prediction.
LiveDeep
受限于Motion识别算法,前面提出的LiveMotion只能作用于有清晰并且容易分别的前景背景边界的视频,其健壮性并不能满足全景直播推流的场景。
Method
LiveDeep处理问题的场景为:
- 视频内容在线生成;
- 没有历史用户数据;
- 预测需要满足实时性的要求;
LiveDeep的设计原则:
- online:在线训练在线预测;
- lifelong:模型在整个视频播放会话中更新;
- real-time:预测带来的处理延迟不能影响推流延迟;
CNN的设计:
- 在推流会话的运行时收集并标注训练数据;
- 以交替迭代的方式进行基于当前视频片段的推理和基于之前视频片段的训练;
- 子采样少部分的代表帧来运行 VP 以满足实时性的要求;
Framework
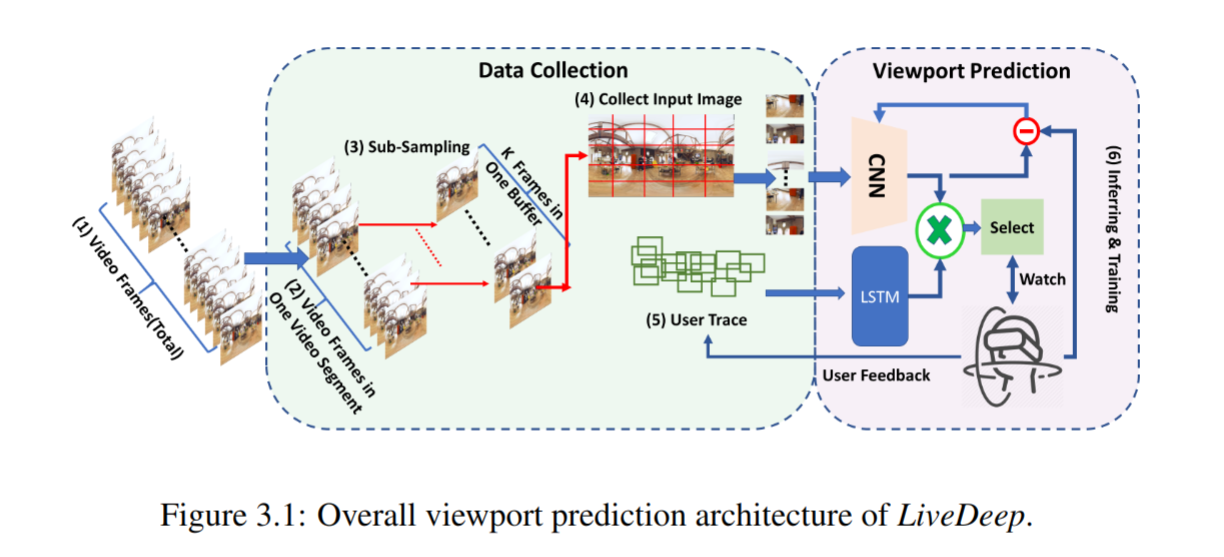
Setup
- 分包器将视频按照 DASH 标准将视频分段,每个段作为训练模型和预测的单元;
- 考虑到不同的视频可能具有不同的帧速率,在每个单元中统一采样 $k$ 帧而非以固定的采样率采样;
- 将每帧图像划分成 $x \times y$ 个分块,最终每个单元中要处理的分块数为 $k \times x \times y$ ;
- 训练集来自于用户的实时反馈,根据实际
FoV和预测FoV之间的差距来标注数据; - 用户的轨迹数据来自于用户的实时头部轨迹,采样的帧与
CNN模块采样的帧同步;
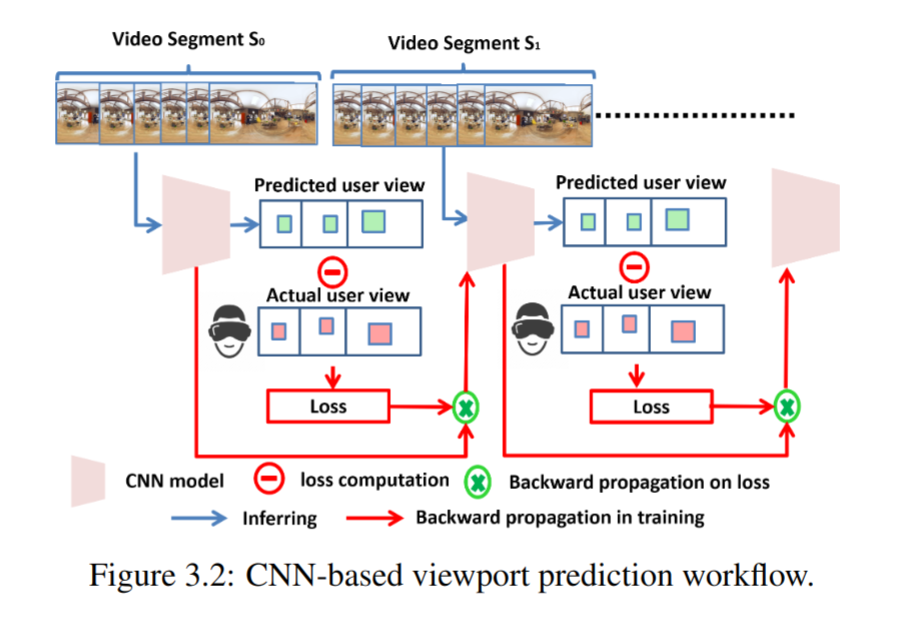
Details
- 在用于训练的图像还没有被标注之前并不能直接预测,所以 CNN 模块只能以随机的权重给出预测结果。用预测结果与实际结果计算出损失值之后以此来更新 CNN 模型;
- LSTM 模型只能以用户观看到视频之后的实际轨迹作为训练的输入输入数据;
- 对下一个片段而言,首先使用两个模块独立做出预测。每个模块的预测都基于子采样之后的 $k$ 个帧;
- 为了产生对整个片段的预测结果,假设相邻的帧之间共享相同的视野中心(时空局部性);
- 取两个模块预测输出的共同的部分作为最终的预测结果;
CNN Module
使用经典的 CNN:VGG 作为骨干网络,修改最后一层,只输出两类:感兴趣的和不感兴趣的。
推理和视口生成
直观上的想法是选择被分类为感兴趣的部分,并且这些所选部分在原始帧中的位置将指示其他帧中可能感兴趣的FoV。
实际上存在的问题是:几乎所有的部分都被分类为感兴趣的一类,最终结果是整个帧被选择作为预测的结果。
所以不直接使用 CNN 网络的输出,而是在被分类为感兴趣的部分中进一步细分。通过对输出的分数排序并选择前 $M$ 份比例的输出作为最终的结果,这样通过控制 $M$ 的大小可以调整精度和消耗的带宽。
训练过程
在传统的监督训练中,训练时间取决于可接受的最低损失值和 epoch 的值。为了满足实时性,LiveDeep采用较高的最低损失值和较低的最大 epoch 值。
High acceptable loss value:因为直接对从被分类为感兴趣的部分中去获取最终结果,所以通过实验证明,损失值应该要比常规的 CNN 更高:设定为 0.2。
The number of epochs:因为直播推流的特殊性,重复的训练并不能持续降低损失,所以采用较小的值:10。
The batch size:受限于训练的图像,将其设定为训练图像的个数即: $k \times x \times y$。
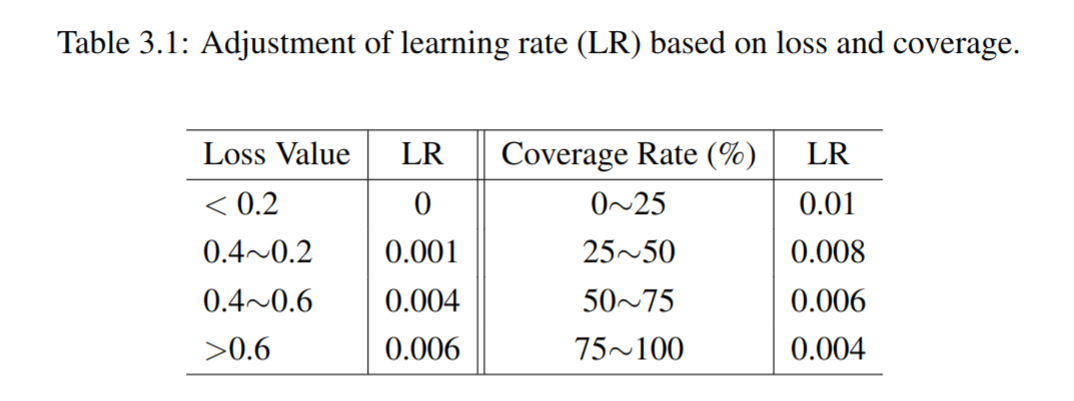
Dynamic learning rate:
LSTM Module
单纯的CNN模型可能会导致对视频内容有强记忆性,而这会使模型在面对新视频内容时需要花较长的时间去接受用户偏好,即对于用户偏好的快速切换不能做出即时响应。而LSTM的模块用于弥补这一缺陷;
采用与原始的LSTM模型相同的训练过程:先用收集的训练数据训练模型然后推断未来的数据。
收集用户在过去的视频片段中的用户轨迹,包括从 $k$ 个子采样帧中的 $k$ 个采样点,因此作为训练数据,同时将每个采样点中每个帧的索引指定为时间戳。最终模型的输出是预测出的分块的索引。
混合模型
将CNN模块得到的输出作为主要的结果,接着结合LSTM模块的输出结果作为最终的预测结果。