LiveObj
LiveDeep方法利用卷积层从视频内容中提取深层特征,不受动态背景的影响。然而在整个推流会话中需要更新一个带有大量权重的巨大的神经网络模型。同时因为没有历史视频和用户的轨迹的数据,模型需要在运行时从随机权重开始训练。而这会导致两个问题:
- 模型需要花很长时间从一次预测错误中恢复;
- 在初始化的阶段预测率成功率很低;
为了解决这两个问题,提出预训练的模型来分析视频内容,对视频的语义进行层次化。
基于对内容的分析,进一步设计了一个轻量级用户模型,将用户偏好映射到不同的视频内容。
用户观看行为分析
在直播推流中,不能通过分析其他用户的行为模式来得到特定用户的ROI,因此只能直接从视频内容本身入手。
通过对视频内容从空间和时间两个维度的分析得出结论:用户的ROI与物体的大小无关,而是很大程度上依赖于物体在视频中的语义,即用户倾向于观看有意义的事物。
这一结论可以给出推断FoV的直觉:基于检测视频中有意义的物体。
Methods
首先提出两种直观的通过分析视频内容的视点预测方法,进一步总结这些方法的局限性,并逐步切换到对LiveObj的讨论。
Basic method
Basic方法检测视频中所有的对象并使用其中心作为预测的中心。
给出每个帧中的 $k$ 个物体, $\vec{O} = [o_1, o_2, o_3, …, o_k]$ ,其中每个 $o_i(i = 1, …, k)$ 表示物体的中心坐标: $o_i = <o^{(x)}_i, o^{(y)}_i>$ 。
最终的预测中心点坐标可以计算出来:
$$ C_x = \frac{1}{k} \sum^{k}_{i=1} o^{(x)}_i;\ C_y = \frac{1}{k} \sum^{k}_{i=1} o^{(y)}_i $$
Over-Cover method
受LiveMotion方法的启发,其创建了不规则的预测FoV来覆盖更多的潜在的区域,Over-Cover的方式预测的FoV会覆盖所有包含物体的区域。
采用YOLOv3来处理帧并检测物体,接着每个检测到的对象生成与该对象共享相同中心的预测子视图,所有子视图的聚合形成最终的预测视口。
Summary for intuitive methods
Basic方式可能会在多个物体的场景中无法正确选择目标;
Over-Cover方式覆盖所有可能的目标来满足较高的精度,但会导致更高的带宽使用量;
Velocity方式能很快的适应用户偏好的变化,但是预测精度在长期预测的情况下会显著下降;
LiveObj Method
Over-Cover方法将所有检测到的目标合并到预测的FoV中而导致冗余问题,而用户一次只能观看其中的几个。
为了解决这个问题,提出基于用户的反馈选择最吸引人的目标,例如用户当前的FoV来形成预测的FoV。
基于这种想法而提出LiveObj,一种基于轨迹的 VP 方式,通过从Over-Cover方法的结果中过滤掉用户更小可能性看到的目标来缩小最终的FoV。
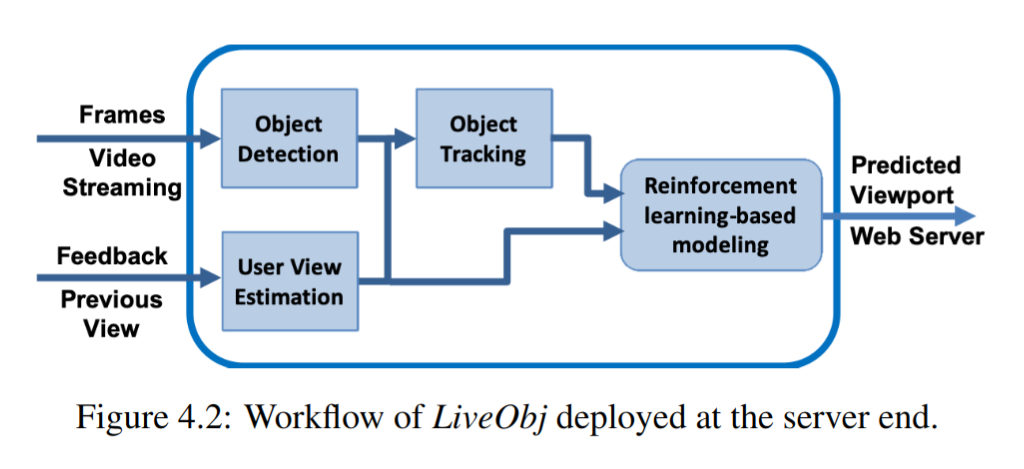
- Object Detection:处理视频帧并检测目标;
- User View Estimation:分析用户反馈并用Velocity的方式估计
FoV; - Object tracking:追踪用户观看的目标;
- RL-based modeling:接受估计出的
FoV和被追踪的目标,最终更新每个分块的状态(选中或未选中)
Object Detection and Tracking
Detection:
YOLOv3;Tracking:追踪的基本假设是用户会在接下来的一段时间内接着观看当前看着的目标。追踪任务在直播推流的运行时完成。因此每隔几秒收集用户反馈,并进一步推断用户之前正在观看的目标,然后据此更新追踪目标。
追踪算法:

User View Estimation
分析用户的反馈处于两个目的:
- 估计未来的用户的
FoV; - 校准当前用户
FoV以及要跟踪的对象;
给出用户反馈(即过去片段中实际的FoV),首先更新用户FoV并分析用户的行为模式,并根据此模式计算出下一帧中的预期用户速度。然后识别更新后的FoV中的对象,这些对象确定为ROI,对象追踪步骤将这些更新用于未来的片段来提高预测精度。
RL-based Modeling
因为预测的误差和用户实际FoV的变化,可能会导致追踪的目标从FoV中消失,而这会使整个预测算法完全失效。所以提出一个基于 RL 的模型来为每个分块建立用户行为模型,旨在最小化预测误差。
出发点是不同的分块有不同的概率包含有意义的目标,并且更可能包含有意义目标的分块通常对目标检测错误更敏感。
将上面的观察形式化为一个策略学习过程 $M$:
$$ M = <S, A, P_{s, a, s’}, R> $$
其中 $S$ 和 $A$ 表示状态和动作, $P_{s, a, s’}$ 是给定状态 $s$ 的情况下选择动作 $a$ 的概率,转移之后的状态为 $s’$ ,$R$ 表示奖励函数。
系统的目标是通过设定不同的 $P_{s, a, s’}$ 的值,来学习每个分块对目标检测误差的不同的敏感性。
状态-价值函数用于估计在为所有可能的状态 $s \in S$ 选择动作 $a$ 时的价值,形式化为:
$$ v = E[Q_{s, a} | S_t = s] $$
$$ Q_{s, a} = R^a_s + \gamma \sum_{s’ \in S} P_{s, a, s’} v $$
其中:$\gamma$ 是奖励参数。
最终的目标是通过计算每个 $P_{s, a, s’}$ 找到最大的 $max(Q_{s, a})$。
而这一过程很耗费时间,因此使用修改之后的Q-learning过程,用贪心的方式来解决最优化问题。
Q-learning过程在直播推流中有别于传统点播中的应用:
- 预测同时基于当前的输入(目标追踪和
FoV估计的结果)和历史状态(分块是否被选择); - 奖励基于用户的反馈在线生成,并且会在整个推流会话中变化,而不是预先设定好的奖励矩阵 $R$ ;
- 由于直播推流中内容的不可提前获取性, $Q$ 表必须在每次预测中更新;
特别的,为每个分块都创建一个 $Q$ 表,对于每个 $Q$ 表有 4 种类型:
- object only;
- object and viewport;
- viewport only;
- no objects or viewport;
将这 4 种类型和 2 种中历史状态(选中或未选中)组合之后,得到每个表中状态 $s$ 的 8 个选项组合;
对每个状态而言,有 2 种动作(选中或不选中),因此每个表有 8 个状态和 2 个动作。
对每个表的奖励基于用户是否看到了分块而更新。
基于状态 $s$ 的对动作 $a$ 的选择转化成了:在相同输入的情况下找到 $max(Q(s, s’))$;

LiveROI
LiveObj的基础是对象检测算法,用于分析视频内容的敏感性。但是其检测性能可能会受到算法、对象的缩放程度和全景视频导致的扭曲失真的影响,进而引起预测误差。类似于LiveObj的出发点,LiveROI的目标是通过使用动作识别来对视频内容进行分析,这会降低预测性能与前面所提因素的敏感性。
使用3D-CNN等预先训练的模型来分析每个分块上的视频内容,以完成动作识别。同时基于NLP技术,使用轻量级用户模型将用户偏好映射到不同的视频内容。
用户对视频内容的偏好
最基本的研究问题是:找到直播视频内容中的有效特征和信号或用户的行为,这些与用户的未来的FoV有强相关关系,因此可以将其作为预测因子。
通过对两个固定主题的视频的实验可以得出:
- 用户花绝大多数的时间在视频中有意义的部分;
ROI在空间上只占整个帧很小的部分;
LiveROI Method
融合视频内容感知和用户偏好反馈(即以用户头部运动轨迹的形式)来预测实时 VR 视频流中的FoV。
主要想法是使用 CV 算法去理解每个分块的内容,除此之外,采用实时的用户反馈方便分块的选择。
需要满足的条件是:所有分块上的视频处理开销应该保持较小,以避免视频冻结和累计的实时延迟。
使用3D-CNN进行视频理解,重点是识别视频中隐含的有意义的动作,动作识别结果用于以自然语言的格式描述视频内容。这种 3D-CNN 模型可以在公共数据集上进行训练,因此具有通用性,以适应各种类型的动作和视频,这使得它可以用于实时 VR 流传输,因为在流传输会话之前没有关于视频内容的先验知识。
但是具有有意义动作的区域可能不是用户最后会确定的FoV,尤其是在目标视频中存在多个有意义动作的情况下。
为了解决这一问题,通过收集用户关于偏好视频内容的实时描述,进一步设计了基于“词/短语”的用户偏好模型。
采用词语嵌入的方法,通过比较两个来源短语的语义相似度,确定最佳匹配区域作为预测FoV,以此来桥接动作识别结果和用户偏好模型。
Workflow
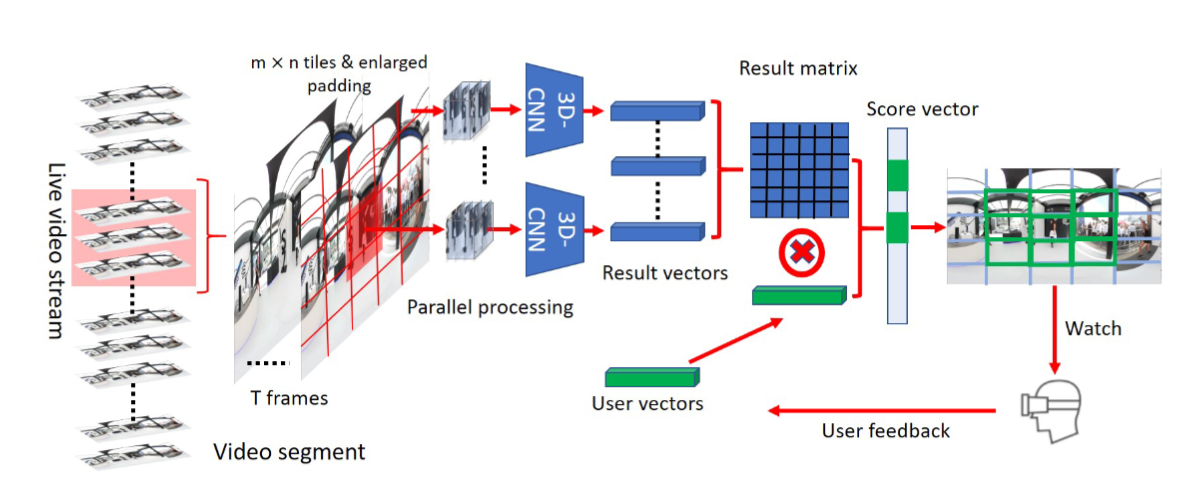
3D-CNN的输入数据包含一批 $T$ 张图像,因此统一在一个视频片段中子采样 $T$ 帧。
每个子采样的帧都划分成 $M \times N$ 个分块,VP 问题定义为确定要包含在FoV中的分块。
为了避免由于分块带来的潜在的信息损失(有意义的动作被划分成多个分块),每个用于动作识别的输入图像是从比原始分块边界更大的区域中所提取出来的,但是将共享与原始分块相同的中心。
3D-CNN模块的输出是动作识别结果,即结果矩阵。
面对 $M \times N$ 个分块,为了满足性能要求,将每个分块的动作识别过程视为相互独立的过程,创建 $m \times n$ 个线程来实现并行识别,每个线程向结果矩阵输出对应分块的结果向量。
在预测的最后一步,生成包含所有分块的预测分数的得分向量。进一步对所有的分数向量进行排序,并定位第 $M$ 个值,该值设定为选择分块进入预测FoV中的阈值。通过控制 $M$ 的大小可以控制预测的FoV的大小,分数向量中的分数表示用户对分块内容的感兴趣程度。
为了计算分数向量,进一步设计用户向量,其中包含描述用户偏好的词或短语。考虑到推流过程中用户可能会改变兴趣,用户向量会基于用户实时轨迹更新。
在给定用户向量和结果矩阵中的词或短语的情况下,考虑到非自然语言中的两个不同的词可能具有相近的含义,不直接进行词比较,而是使用词分析来计算其相关性。
CNN Model
采用ECO lite模型完成 VR 直播推流中的动作识别。所有来自同一视频片段的图像都被储存在一个缓冲帧集合中。
ECO lite模型为 2D CNN 提取特征图的任务收集工作帧集合(分别由前一视频片段和当前视频片段的缓冲帧集合的后半部分和前半部分组成),在下一个阶段,从每个片段获得的特征图被堆叠到更高的表示中,之后被送到之后的 3D CNN 中用于最终的动作预测。具体的识别过程中同样使用多线程并行处理,处理 1 帧图像是每次创建和分块数相同的线程,为每个分块都初始化一个ECO lite模型。
显然预训练的模型不能为直播推流提供正确的推理结果,但是它可以看作是对视频内容的验证,即:给定一种类型的视频内容,其实其本身被误分类了,但在同一个模型之下它总是会被分类进在整个推流过程中都有相近分数的簇中。
利用这个特性,基于动作识别模型提供的对视频内容的描述,进一步设计动态的用户模型来映射用户偏好到不同的视频内容上。
NLP Model
为了桥接动作识别和用户偏好向量,必须分析词/短语之间的相似性。
然而现有的 ML 算法不能直接处理生数据,因为输入必须是数值。为了解决这个问题,采用单词嵌入技术,使用多种语言模型以数值向量的形式来表示单词,以此来确保有相近意义的词有相近密度的表示。
具体处理时使用Phrase2Vec作为 NLP 模块的模型(作为Word2Vec的扩展,能更好的分析两个短语之间的相似性)。
用户模型与预测
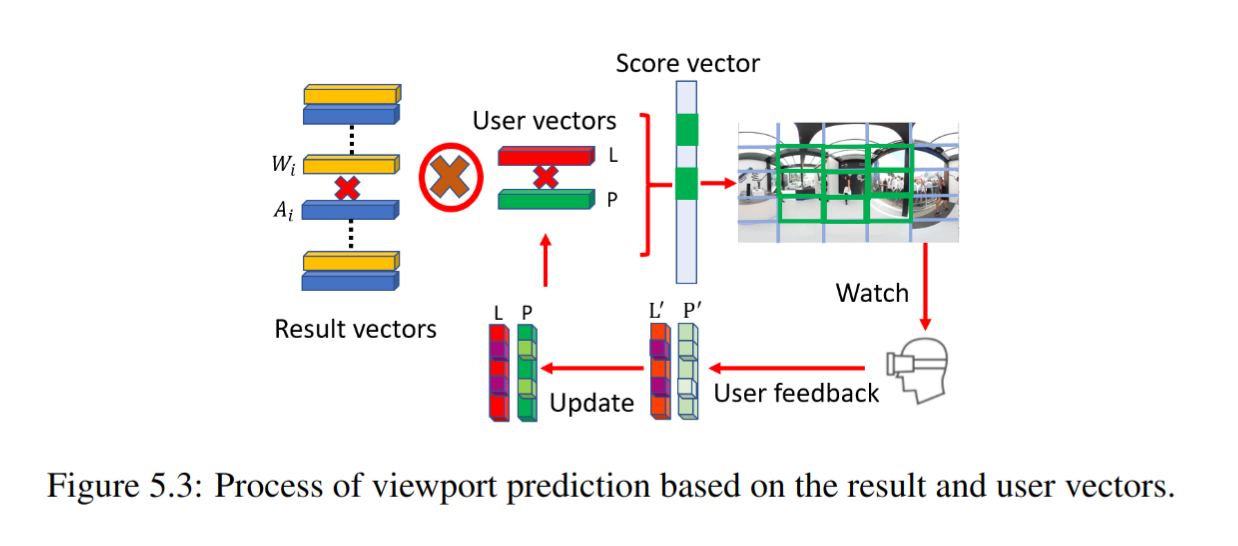
图 5.3 阐明了基于结果向量和用户向量的预测过程。由动作识别得出的结果向量,包括一个动作向量 $A$ 和一个权重向量 $W$ 。用户向量包括偏好向量 $P$ 和可能性向量 $L$ 。$A$ 和 $P$ 包含词和短语,描述了视频内容和用户偏好。 $W$ 和 $L$ 分别由表示神经网络对动作结果的置信度和用户对视频内容的参考可能性的值组成。
假设每帧 25 个分块,CNN 模块的输出结果是 25 个 $A$ 向量和 25 个 $W$ 向量;对与用户偏好,只使用 1 个 $P$ 向量和 1 个 $L$ 向量。
最终的分数向量 $S$ 计算为每个 $A$ 和 唯一的 $P$ 之间的相关性。结果也受相应的 $W$ 和 $L$ 的影响而调整。
假设余弦相似性函数为 $\rho$ ,那么 $A$ 和 $P$ 中的每个 $a_i$ 和 $p_i$ 的计算可以表示为:
$$ {\rho}_i (a_i, p_i) = Phrase2Vec(a_i, p_i) $$
设定每个向量中包含 5 个元素,分数向量 $S$ 计算为:
$$ S = L \cdot W \cdot \sum {\rho} (A, P) $$
对应于 25 个分块,最终的分数向量中包含 25 个元素。 $s_k$ 表示 $k_{th}$ 分块的分数值,详细算法:

分数向量更新完毕之后就可以获得每个分块内容和用户偏好之间的相关性,用帧上每个分块的亮度来做可视化:

将分数向量中的元素从高到低排序,选定 $\frac{1}{3}$ 作为阈值,将前 $\frac{1}{3}$ 的分块看作相同的分数等级作为最后的预测区域。
为了应对推流过程中用户偏好的变化,为分数向量的计算设计动态加权的用户偏好向量。
设定用户偏好向量 $P$ 的大小与动作向量 $A$ 的大小相同,一旦系统获取到用户实际的FoV位置,就计算其视野中心并定位到相应的分块,使用前一视频片段中该选中分块的动作向量 $A’$ 来更新用户的偏好向量。