论文概况
Level:Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 2019
Keywords:Viewport prediction, content-based motion tracking, dynamic user interest model
Workflow
- Tracking:VR motion 追踪算法:应用了高斯混合模型来检测物体的运动。
- Recovery:基于反馈的错误恢复算法:在运行时考虑实际的用户 viewport 来自动更正潜在的预测错误。
- Update:viewport 动态更新算法:动态调整预测的 viewport 大小去覆盖感兴趣的潜在 viewport,同时尽可能保证最低的带宽消耗。
- Evaluation:经验用户/视频评估:构建 VR viewport 预测方法原型,使用经验 360°视频和代表性的头部移动数据集评估。
全景直播推流的预备知识
VR 推流直播
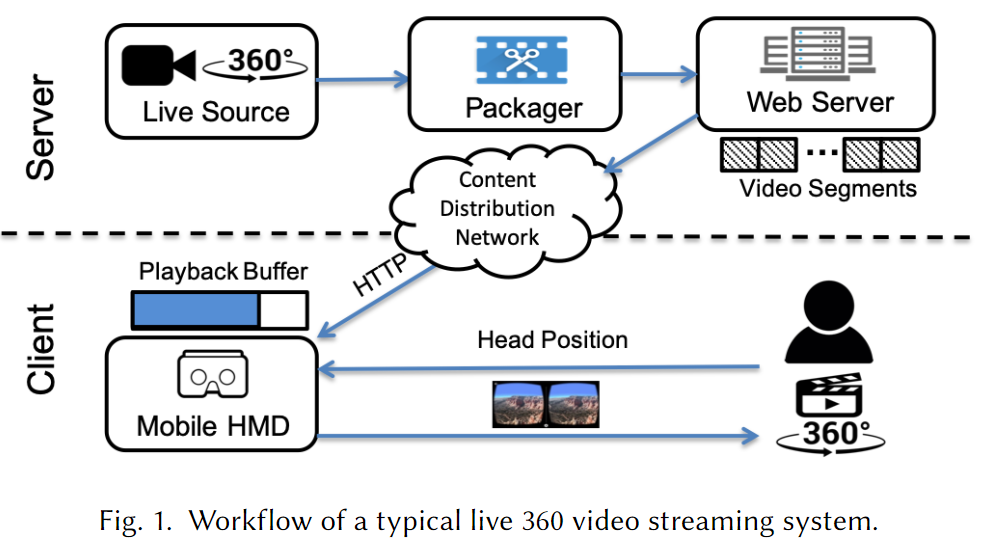
相比于传统的 2D 视频推流的特别之处:
- VR 系统是交互式的,viewport 的选择权在客户端;
- 呈现给用户的最终视图是整个视频的一部分;
用户头部移动的模式
在大量的 360°视频观看过程中,用户主要的头部移动模式有 4 种,使用$i-j\ move$来表示;
其中$i$表示处于运动中的物体数量;$j$表示所有运动物体的运动方向的平均数。
- $1-1\ move$:单个物体以单一方向移动;
- $1-n\ move$:单个物体以多个方向移动;
- $m-n\ move$:多个物体以多个方向移动;
- $Arbitrary\ move$:用户不跟随任何感兴趣的物体而移动,viewport 切换随机;
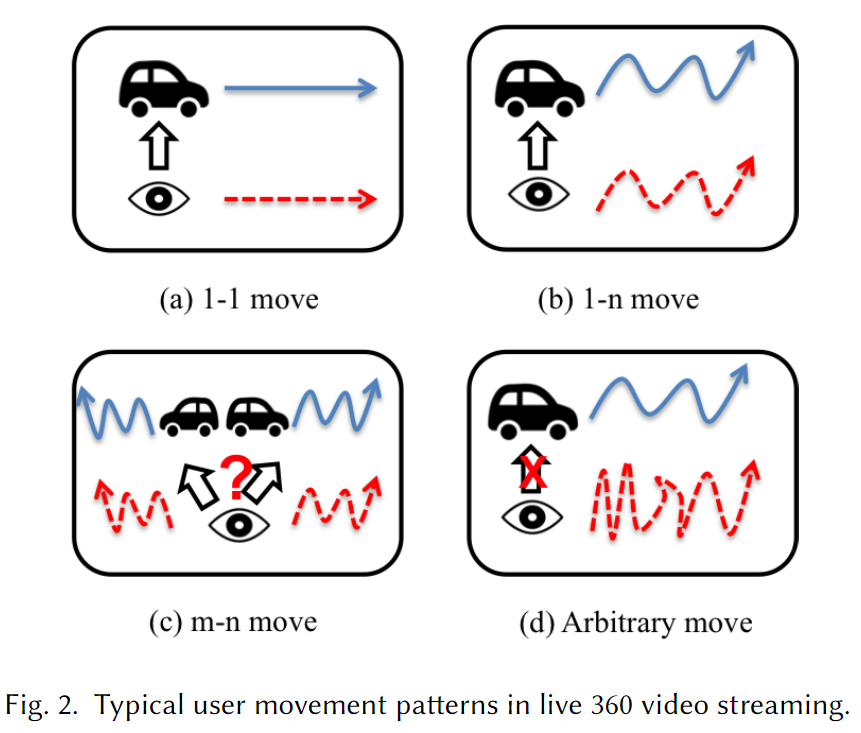
现有的直播 VR 推流中的 viewport 预测方法是基于速度的方式,这种方式只对$1-1\ move$这一种模式有效。
本方案的目标是提出对 4 种模式都有效的预测策略。
系统架构
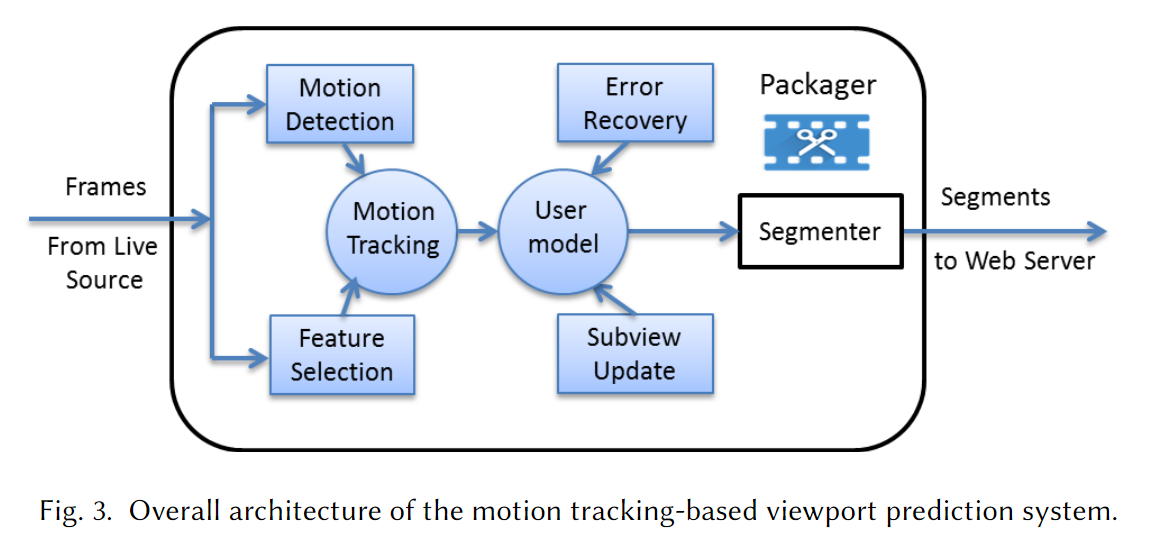
理论创新
核心功能模块:
motion detection:区分运动物体与静止的背景。
feature selection:选择代表性的特征并对运动物体做追踪。
这两个模块使系统能识别用户可能感兴趣的 viewport。
使用贝叶斯方法分析用户观看行为并形式化用户的兴趣模型。
使用错误恢复机制来使当预测错误被检测到时的预测 viewport 去适应实际的 viewport,尽管不能消除预测错误但是能避免在此基础上进一步的预测错误。
使用动态 viewport 更新算法来产生大小可变的 viewport,通过同时考虑跟踪到的 viewport 轨迹和用户当前的速度(矢量)。
这样,即使用户的运动模式很复杂也能有更高的概率去覆盖潜在的视图。
具体实施
虽然提出的运动追踪和错误处理机制是计算密集型的任务,但是这些组件都部署在 video packager 中,运行在服务端。
将生成 VR 视图的工作负载移动到服务端,进一步减少了客户端的计算开销以及网络开销。
形式化
基于运动轨迹的 viewport 预测
使用GMM完成运动检测,使用Shi-Tomasi algorithm解决运动轨迹跟踪问题。

运动检测
GMM 前景提取
特征选取与过滤
采用 Shi-Tomasi algorithm 从视频中检测代表性的特征,直接检测得到的代表性特征数量较多而难以追踪。
采用两种过滤的方法来减少要追踪的特征数量。
比较当前帧和前一帧的特征,只保留其共有的部分。
采用第 1 步中运动检测的方式,只保留运动的部分。
viewport 生成
经过选择和过滤之后的特征通常分布在不能被单一用户视图所覆盖的广阔区域中。
在整个 360°视频中可能存在多个运动的物体,即$m-n\ move$。
提出一种系统的方式来产生用户最可能跟随观看的 viewport。
直觉是用户更可能将大部分注意力放在两种类型的物体上:
- 离用户更近的物体。
- 就物理形状而言更“重要”的物体。
这两种类型的物体大多包含最密集和最大量的特征,因此通过所有特征的重心来计算预测用户视图的中心。
对于剩余的特征列表:$\vec{F} = [f_1, f_2, f_3, …, f_k]$,其中$f_i(i = 1 … k)$表示特征$f_i = <f^{(x)}_i, f^{(y)}_i>$的像素点坐标,则预测出的 viewport 中心坐标可以计算出来:
$$ l_x = \frac{1}{k} \sum^k_{i=1} f^{(x)}_i;\ l_y = \frac{1}{k} \sum^k_{i=1} f^{(y)}_i. $$
考虑到即使预测的 viewport 中包含用户观看的物体,预测得到的 viewport 也可能会与实际的 viewport 存在差异。
所以预测的 viewport 可能比实际的 viewport 要大,所以使用缩放因子$S_c$来产生预测的 viewport。
给出用户 viewport 的大小$S_{user}$,预测的 viewport 可以通过$S_{pre} = S_c \cdot S_{user}$计算出来。
基于用户反馈的错误恢复
video packager 可以通过 HMD 和 web 服务器通过反向路径从用户处检索用户实际视图的反馈信息。
基于反馈的错误恢复机制在以下两种场景中表现良好:
没有运动的物体
如果没有检测到运动的物体,则用户很可能是在观看静止的物体,这会导致基于运动目标的 viewport 预测失败。
在这种场景中,可以认为视频内容已经不再是决定用户 viewport 的因素,而只取决于用户自身的行为。
因此采用基于速度的方式来预测 viewport。(这样的决策可以在运动检测模块没有检测到运动物体时就做出)
一旦从反馈路径上得到用户信息,可以产生用户 viewport 位置向量:$\vec{L} = [l_1, l_2, l_3, …, l_M]$,其中$l_i$表示第$i$个帧中用户 viewport 的位置,$M$表示视频播放缓冲区中的帧数。那么可以计算 viewport 速度:
$$ \vec{V} = \frac{\vec{(l_2 - l_1)} + \vec{(l_3 - l_2)} ….(l_M - l_{M-1})}{M-1} = \frac{(\vec{l_M - l_1})}{M-1} $$
下一帧的预测位置$L_{M=1}$也可以计算出来:$$ l_{M+1} = l_M + \vec{V} $$
预测视图与实际视图的不匹配
一旦运动追踪策略检测到用户实际的视图和预测的视图不同,就会触发恢复机制去追踪用户实际在看着的物体。
可以使用运动追踪方式确定用户实际观察的物体的速度。
给出前一帧匹配的特征$\vec{FA} = [fA_1, fA_2, fA_3, …, fA_p]$和当前帧的特征$\vec{FB} = [fB_1, fB_2, fB_3, …, fB_p]$,可以计算出速度:
$$ V_x = \frac{1}{p} (\sum^p_{i=1} fB^{(x)}_i - \sum^p_{i=1}fA^{(x)}_i),
V_y = \frac{1}{p} (\sum^p_{i=1} fB^{(y)}_i - \sum^p_{i=1}fA^{(y)}_i), $$假设预测的 viewpoint 是$(l_x, l_y)$,修改之后的 viewpoint 是$(l_x + V_x,\ l_y + V_y)$。
动态 viewport 更新
前述的错误恢复机制发生在 viewport 预测错误出现之后,任务是避免未来更多的错误。
动态的 viewport 更新则努力避免 viewport 预测错误。
关键思想是扩大预测的 viewport 大小,以高概率去覆盖$m-n\ move$和$arbitrary\ move$下所有潜在的运动目标;更重要的是动态调整视图的大小去获得更高效的带宽利用率。
对于一个 360°全景视频,将 360°的帧均分为$N = n \times n$个网格,每个网格看作是一个 tile,预测的 viewport 即为$N$个 tile 的子集。
使用贝叶斯方法分析用户的观看行为,每个 tile 分配一个独立的贝叶斯模型,所以每个 tile 可以独立更新。
设$X$表示用户 viewport,$Y$表示静态内容,$Z$表示运动物体。
未来的用户 viewport 可以以条件概率计算为$P(X|Y,\ Z)$,$Y$与$Z$相互独立。
用户的 viewport 可以通过反馈信息得出$P(X)$;用户观看静态特征可以表示为$P(X|Y)$;用户观看动态特征可以表示为$P(X|Z)$。
$P(X|Y, Z)$可以计算为:
$$ P(X|Y, Z) = \frac{P(Y|X) \cdot P(Z|X) \cdot P(X)}{P(Y, Z)} $$
只要用户开始观看,对于 tile $T_i$,就能得到其先验概率$P(Y_i|X_i)$和$P(Z_i|X_i)$,进而根据贝叶斯模型计算出$P(X|Y, Z)$。
为每个 tile 定义两种属性:
- 当前状态:表示此 tile 是否属于预测的 viewport(属于标记为$PREDICTED$,不属于标记为$NONPREDICTED$)。
- 生存期:表示此 tile 会在 view port 中存在多长时间(例如定义 3 种等级:$ZERO$,$MEDIUM$,$HIGH$,实际的定义划分可以根据具体的用户和视频设定)。
预测步骤
按照形式化中提出的 3 步,分为系统初始化、帧级别的更新、缓冲区级别的更新。
系统初始化
初始化阶段中,view 更新算法将所有的$N$个 tile 标注为$PREDICTED$,并将生存期设置为$MEDIUM$,即系统向用户发送完整的一帧作为自举。
这样设定的原因在于:当用户第一次启动视频会话时,允许“环视”类型的移动,这可能会覆盖 360°帧的任意 viewport。
帧级别的更新
给定一帧,应用修改后的 motion 追踪算法在运动区域中选择特征,而不使用特征的密度做进一步的过滤。
使用有多个 tile 的多个视图来覆盖一个放大的区域,该区域包含作为预测 viewport 的移动对象上的所有特征,这样就能适应$m-n\ move$中的用户行为。
设计帧级别的算法标记选择的 tile 作为$PREDICTED$并设置其生存期为$HIGH$(直觉上讲运动中的物体或用户所感兴趣的静态特征会更以长时间保留在 viewport 之中)。
缓冲区级别的更新
以缓冲区长度为间隔检索用户的实际视图,基于此可以对 tile 的两种属性做出调整。
- 对于与用户实际视图重叠的 tile,设置为$PREDICTED$和$HIGH$。
- 对于用户实际视图没有出现但出现在预测的视图中的 tile,生存期减 1,如果生存期减为$ZERO$,就重设其状态为$NONPREDICTED$,将其从预测的 viewport 中移除。
