论文概况
Link:QoE-driven Mobile 360 Video Streaming: Predictive View Generation and Dynamic Tile Selection
Level:ICCC 2021
Keywords:QoE maximization,Trajectory-based viewport prediction,Dynamic tile selection,Differential weight on FOV tiles
系统建模与形式化
视频划分
先将视频划分成片段:$\Iota = {1, 2, …, I}$表示片段数为$I$的片段集合。
接着将片段在空间上均匀划分成$M \times N$个 tile,FOV 由被用户看到的 tile 所确定。
使用 ERP 投影,$(\phi_i, \theta_i),\ \phi_i \in (-180\degree, 180\degree], \theta_i \in (-90\degree, 90\degree]$来表示用户在第$i$个片段中的视点坐标。
播放过程中记录用户头部运动的轨迹,积累的数据可以用于 FOV 预测。
跨用户之间的 FOV 轨迹可以用于提高预测精度。
QoE 模型
前提
视频编解码器预先确定,无法调整每个 tile 的码率。
实现
- 每个 tile 都以不同的码率编码成不同的版本。
- 每个 tile 都有两种分辨率的版本。
QoE 内容
客户端收到的视频质量和观看时的卡顿时间。
质量形式化
对于每个片段$i \in \Iota$,$S_i = {\tau_{i, j}}_{j=1}^{M \times N}$是用来表示用户实际看到的 tile 的集合的向量。
$\tau_{i, j} = 1$表示第$i$个段中的第$j$个 tile 被看到;$\tau_{i, j} = 0$表示未被看到。
同样的, $\tilde{S}_i = {\tilde{\tau}_{i, j}}_{j = 1}^{M \times N}$ 表示经过 FOV 预测和 tile 选择之后成功被传送到用户头戴设备上的 tile 集合的向量。
$\tilde{\tau}_{i, j} = 1$表示第$i$个段中的第$j$个 tile 被用户接收;$\tilde{\tau}_{i, j} = 0$表示未被接收。
第$i$个段的可感知到的质量可以表示为:
$$ Q_i = \sum_{j = 1}^{M \times N} p_{i, j}b_{i, j}\tau_{i, j}\tilde{\tau}_{i, j} $$
$b_{i, j}$表示第$i$个片段的第$j$个 tile 的码率;$p_{i, j}$表示对不同位置 tile 所分配的权重;
关于权重$p_{i, j}$
研究表明用户在全景视频 FOV 中的注意力分配并不是均等的,越靠近 FOV 中心的 tile 对用户的 QoE 贡献越大。
下面讨论单个片段的情况:用$(\phi_j, \theta_j)$表示 tile 中心点的坐标,并映射到笛卡尔坐标系上$(x_j, y_j, z_j)$:
$$ x_j = cos\theta_jcos\phi_j,\ y_j = sin\theta_j,\ z_j = -cos\theta_jsin\phi_j $$
则两个 tile 之间的半径距离$d_{j, j’}$可以表示为:
$$ d_{j, j’} = arccos(x_j x_{j’} + y_j y_{j’} + z_j z_{j’}) $$
对于第$i$个片段,假设用户 FOV 中心的 tile 为$j^*$,那么第$j$个 tile 的权重可以计算出来:
$$ p_{i, j} = (1 - d_{j, j^*} / \pi) \tau_{i, j} $$
卡顿时间形式化
当$\tilde{\tau}_{i, j}$与$\tau_{i, j}$出现分歧时,用户就不能成功收到请求的 tile,头戴设备中显示的内容就会被冻结,由此导致卡顿。
对于任意的片段$i \in \Iota$,相应的卡顿时间$D_i$可以计算出来:
$$ D_i = \frac{\sum_{j = 1}^{M \times N} b_{i, j} \cdot [\tau_{i, j} - \tilde{\tau}_{i, j}]^+}{\xi} $$
$[x]^+ = max \lbrace x, 0 \rbrace $;$\xi$表示可用的网络资源(已知,并且在推流过程中保持为常数)
卡顿发生于在播放时,用户 FOV 内的 tile 还没有被传输到用户头戴设备中的时刻,终止于所有 FOV 内 tile 被成功传送的时刻。
质量与卡顿时间的结合
$$ max\ QoE = \sum_{i = 1}^I (Q_i - wD_i) $$
$w$表示卡顿事件的惩罚权重。例如,w=1000 意味着 1 秒视频暂停接收的 QoE 惩罚与将片段的比特率降低 1000 bps 相同。
联合 viewport 预测与 tile 选择
联合框架包括 viewport 预测和动态 tile 选择两个阶段。
viewport 预测阶段集成带有注意力机制的 RNN,接收用户的历史头部移动信息作为输入,输出每个 tile 出现在 FOV 中的可能性分布。
选择 tile 阶段为预测的输出建立的上下文空间,基于上下文赌博机学习算法来选择 tile 并确定所选 tile 的质量版本。
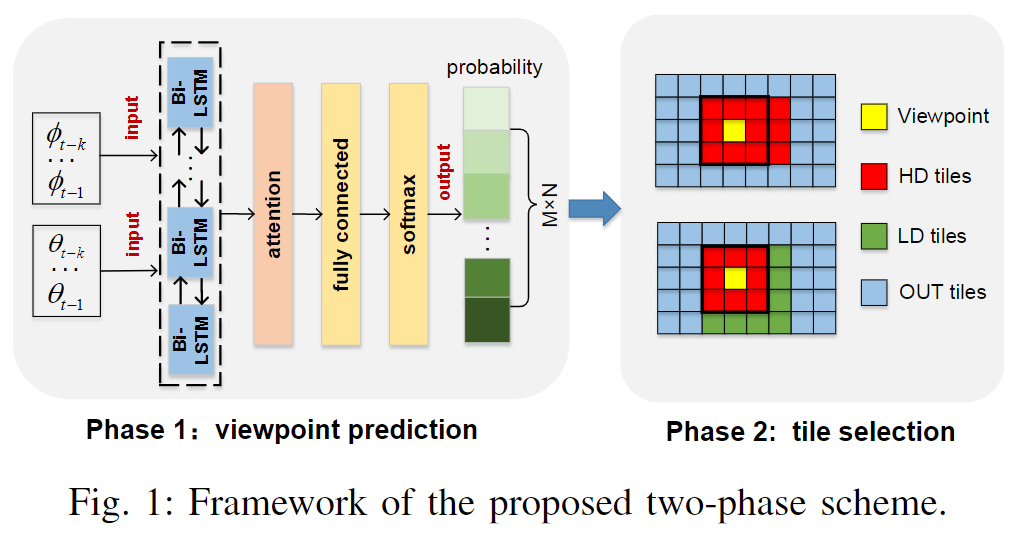

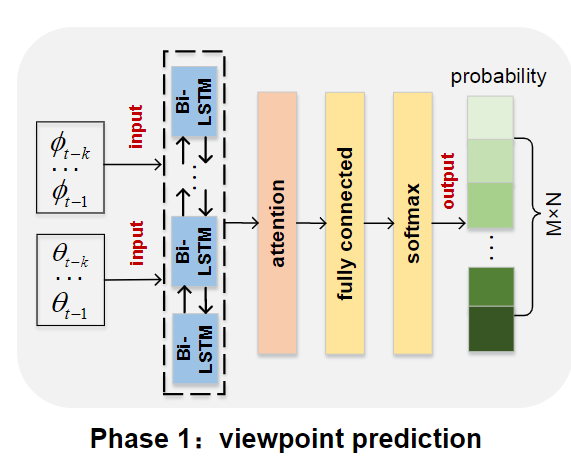
Viewport 预测
FOV 预测问题可以看作是序列预测问题。
不同用户观看相同视频时的头部移动轨迹有强相关性,所以跨用户的行为分析可以用于提高新用户的 viewport 预测精度。
被广泛使用的 LSTM 的变体——Bi-LSTM(Bi-directional LSTM)用于 FOV 预测。
输入参数构造
为了构造 Bi-LSTM 学习网络,需要对不同用户的 viewpoint 特性作表征。
在用户观看事先划分好的$I$个片段时,记录每个片段对应的 viewpoint 坐标:
$\Phi_{1:I} = {\phi_i}^I_{i = 1},\ \Theta_{1:I} = {\theta_i}^I_{i=1}$
预测时使用的历史信息的窗口大小记为$k$;
对于第$i, (i > k)$个片段,相应的 viewpoint 特性由$\Phi_{i-1:i-k}$和$\Theta_{i-1:i-k}$所给出;
列索引$m_i$和行索引$n_i$作为 viewpoint tile $(\phi_i, \theta_i)$的标签,由独热编码表示;
通过滑动预测的窗口,所看到的视频片段的特性和标签可以被获取。
LSTM 网络构造
整个网络包含 3 层:
- 遗忘门层决定丢弃哪些信息;
- 更新门层决定哪类信息需要存储;
- 输出门层过滤输出信息。
为了预测用户在第$i$个段的 viewpoint,LSTM 网络接受$\Phi_{i-1:i-k}$和$\Theta_{i-1:i-k}$作为输入;输出行列索引;
$$ m_i = LSTM(\theta_{i-k}, …, \phi_{i-1}; \alpha) $$
$$ n_i = LSTM(\theta_{i-k}, …, \theta_{i-1}; \beta) $$
$\alpha, \beta$是学习网络的参数;分类交叉熵被用作网络训练的损失函数。
Bi-LSTM 的特殊构造
将公共单向的 LSTM 划分成 2 个方向。
当前片段的输出利用前向和反向信息,这为网络提供了额外的上下文,加速了学习过程。
双向的 LSTM 不直接连接,不共享参数。
每个时间槽的输入会被分别传输到前向和反向的 LSTM 中,并分别根据其状态产生输出。
两个输出直接连接到 Bi-LSTM 的输出节点。
引入注意力机制为每步时间自动分配权重,从大量信息中选择性地筛选出重要信息。
将 Softmax 层堆叠在网络顶部,以获取不同 tile 的 viewpoint 概率。
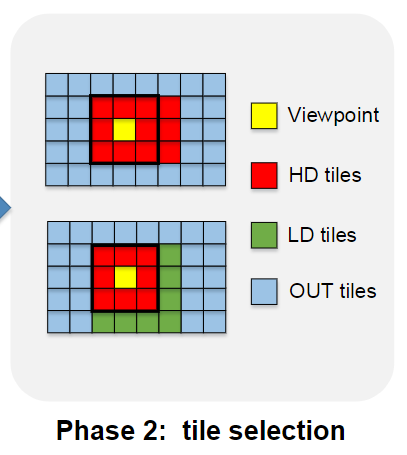
动态 tile 选择
使用上下文赌博机学习算法来补偿 viewport 预测错误对 QoE 造成的影响。
上下文赌博机学习算法概况
上下文赌博机学习算法是一个基于特征的 exploration-exploitation 技术。
通过在多条手臂上重复执行选择过程,可以获得在不同上下文中的每条手臂的回报。
通过 exploration-exploitation,目标是最大化累积的回报。
组成部分形式化
上下文
直觉上讲,当预测的 viewpoint 不够精确时,需要扩大 FOV 并选择更多的 tile 进行传输。
为了做出第$i$个片段上的预测 viewpoint 填充决策,定义串联的上下文向量:
$c_i = [f^s_i, f^c_i]$,$f^s_i$表示自预测的上下文,$f^c_i$表示跨用户之间的预测上下文。
预测输出的用户$u$的 viewpoint tile 索引用$[\tilde{m}^u_{i-1}, \tilde{n}^u_{i-1}]$表示;
实际的用户$u$的 viewpoint tile 索引用$[m_{i-1}^u, n_{i-1}^u]$表示;
那么对第$i$个片段而言,自预测的上下文可以计算出来:
$$ f_i^s = [|m_{i-1}^u - \tilde{m}^u_{i-1}|, |n_{i-1}^u - \tilde{n}^u_{i-1}|] $$
跨用户的上下文信息获取:使用 KNN 准则选择一组用户,其在前$k$个片段中的轨迹最接近用户$u$的轨迹。
使用$\zeta$表示获得的用户集合,使用
$$E_{\zeta_u}(m_i) = \frac{1}{|\zeta_u|}\sum_{u \in \zeta_u} |m_i^u - \tilde{m}_i^u|$$
$$E_{\zeta_u}(n_i) = \frac{1}{|\zeta_u|}\sum_{u \in \zeta_u}|n_i^u - \tilde{n}_i^u|$$
表示预测误差,则:
$$ f_i^u = [E_{\zeta_u}(m_i), E_{\zeta_u}(n_i)] $$
手臂
根据从第一个阶段得到的每个 tile 的可能性分布,所有的 tile 可以用倒序的方式排列。
最高可能性的 tile 被看作 FOV 的中心,高码率以此 tile 为中心分配。
剩余的带宽用于扩展 FOV,低可能性的 tile 被顺序选择来扩展 FOV 直至带宽耗尽。
手臂的状态$a \in {0, 1}$表示 tile 选择的策略:
- $a = 0$表示 viewpoint 预测准确,填充 tile 分配了高质量;
- $a = 1$表示 viewpoint 预测不准确,填充 tile 分配的质量较低,为了传送尽可能多的 tile 而减少卡顿;
回报
给定上下文$c_i$,选择手臂$a$,预期的回报$r_{i, a}$建模为$c_i$和$a$组合的线性函数:
$$ \Epsilon[r_{i, a}|c_{i, a}] = c_{i, a}^T \theta_a^* $$
未知参数$\theta_a$表示每个手臂的特性,目标是为第$i$个片段选择最优的手臂:
$$ a_i^* = \underset{a}{argmax}\ c_{i, a}^T \theta_a^* $$
使用LinUCB算法做出特征向量的精确估计并获取$\theta_a^*$。
实验评估
评估准备
- 使用现有的viewpoint 轨迹数据集,所有视频被编码为至少每秒 25 帧,长度为 20 到 60 秒;
- 视频每个片段被划分为$6 \times 12$的 tile,每个的角度是$30\degree \times 30\degree$;
- 初始 FOV 设定为$90\degree \times 90\degree$,在 viewpoint 周围是$3 \times 3$的 tile;
- 每个片段的长度为 500ms;
- 默认的预测滑动窗口大小$k = 5$;
- HD 和 LD 版本分别以按照 HEVC 的$QP={32, 22}$的参数编码而得到;
- 训练集和测试集的比例为$7:3$;
- Bi-LSTM 层配置有 128 个隐单元;
- batch 大小为 64;
- epoch 次数为 60;
性能参数
预测精度
视频质量
由传送给用户的有效码率决定:例如实际 FOV 中的 tile 码率总和
卡顿时间
规范化的 QoE
实际取得的 QoE 与在 viewpoint 轨迹已知情况下的 QoE 的比值
对比目标
- 预测阶段——预测精度
- LSTM
- LR
- KNN
- 取 tile 的阶段——规范化的 QoE
- 两个阶段都使用纯 LR
- 只预测而不做动态选择
- 预测阶段——预测精度