论文概况
Link:Sequential Reinforced 360-Degree Video Adaptive Streaming With Cross-User Attentive Network
Level:IEEE Transactions on Broadcasting 2021
Keywords:Cross-user vp, Sequential RL ABR
主要工作
- 使用跨用户注意力网络
CUAN来做 VP; - 使用
360SRL来做 ABR - 将上面两者集成到了推流框架中;
VP
Motivation
形式化 VP 问题如下:
给出 $p^{th}$ 用户的 $1-t$ 时间内的历史视点坐标 $L^{p}_{1:t} = \lbrace l^p_1, l^p_2, …, l^p_t \rbrace$ ,其中 $l^p_t = (x_t, y_t), x_t \in [-180, 180]; y_t \in [-90, 90]$ ;
同一视频的不同用户视点表示为 $L^{1:M}_{1:t+T}$ , $M$ 表示其他用户的数量;
目标是预测未来的 $T$ 个时刻的视点位置 $L^p_i, i = t+1, …, t+T$ ;
最终可以用数学公式表达为:
$$ \underset{F}{min} \sum^{t+T}_{k = t+1} {\parallel l^p_k - \hat{l}^p_k \parallel}_1 $$
现有的用KNN做的跨用户预测基于 LR 的模型,而 LR 的模型很容易产生偏差,所以为了增强KNN的性能,同时考虑单用户的历史视点轨迹和跨用户的视点轨迹。
- 提出一种注意力机制来自动提取来自其他用户视口的有用信息;
- 对于与当前用户有相似偏好的用户轨迹信息给与更多的注意;
- 相似性通过基于过去时间段内其他用户的轨迹计算出来;
Design
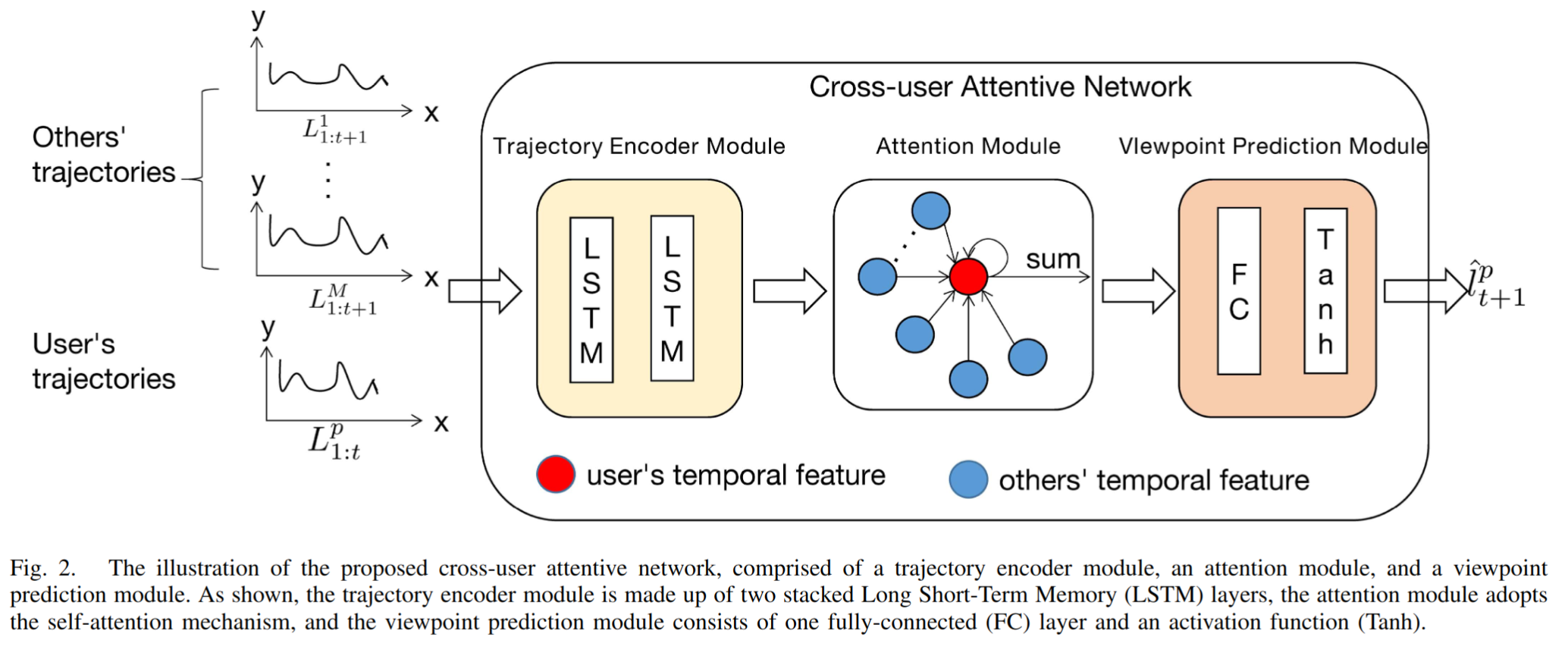
轨迹编码器模块从用户的历史视点位置提取时间特征;
使用
LSTM来编码用户的观看路径;为了预测 ${(t+1)}^{th}$ 帧的视点位置,首先向
LSTM输入 $p^{th}$ 用户的历史视点坐标:$$ f^{p}_{t+1} = h(l^p_1, l^p_2, …, l^p_t) $$
$h(\cdot)$ 是
LSTM的输入输出函数;接着使用相同的
LTSM编码其他用户的观看轨迹:$$ f^{i}_{t+1} = h(l^i_1, l^i_2, …, l^i_{t+1}), i \in \lbrace 1, …, M \rbrace $$
注意力模块从其他用户的视点轨迹中提取与 $p^{th}$ 用户相关的信息
首先推导出 $p^{th}$ 用户和其他用户之间的相关系数:
$$ s^{pi}_{t+1} = z(f^{i}_{t+1}, l^{p}_{t+1}), i \in \lbrace 1, …, M \rbrace \cup \lbrace p \rbrace; $$
$s^{th}_{t+1}$ 表示 $p^{th}$ 用户和 $i^{th}$ 用户之间的相似性;$z()$ 由内积运算建模(还可用其他方式建模比如多个 FC 层);
接着将相关系数规范化:
$$ {\alpha}^{pi}_{t+1} = \frac{e^{s^{pi}_{t+1}}}{\sum_{i \in \lbrace 1,… M \rbrace \cup {\lbrace p \rbrace}^{e^{s^{pi}_{t+1}}}}} $$
最后得到融合特征:
$$ g^{p}_{t+1} = \sum_{i \in {\lbrace 1,…M \rbrace \cup \lbrace p \rbrace}} {\alpha}^{pi}_{t+1} \cdot f^{i}_{t+1} $$
融合特征被最后用于 VP。
VP 模块预测 ${(t+1)}^{th}$ 帧的视点位置
$$ \hat{l}^{p}_{t+1} = r(g^{p}_{t+1}) $$
函数 $r(\cdot)$ 由一层 FC 建模。值得注意的是,对应于未来 T 帧的视点是以滚动方式预测的。
Loss
损失函数定义为预测的视点位置和实际视点位置之间的所有绝对差异的总和:
$$ L = \sum^{t+T}_{i=t} {|\hat{l}^p_i - l^p_i|}_1 $$
Details
- 使用
PyTorch实现; - 函数 $h(\cdot)$ 由两个堆叠的
LSTM层组成,两者都有 32 个神经元; - 函数 $r(\cdot)$ 包含一个带有 32 个神经元的 FC 层,接着是
Tanh函数; - 历史视点和未来视点的长度设定为 1 秒和 5 秒;
- 每次迭代从数据集中随机产生 2048 个样本;
- 所有训练变量的优化函数采用
Adam; - $\beta_1 = 0.9, \beta_2 = 0.999, \epsilon = 10^{-8}$;
- $learning\ rate = 10^{-3}, training\ epoch = 50$;
ABR
Formulation
全景视频被切分成 $m$ 个长度为 $T$ 秒的视频片段,每个视频片段空间上划分成 $N$ 个分块,分别以 $M$ 个不同的码率等级编码。因此对于每段有 $N \times M$ 个可选的编码块。
ABR 的目标是为每个片段找到最优的码率集 $X = \lbrace x_{i, j} \rbrace \in Z^{N \times M}$ ( $x_{i, j} = 1$ 意味着为 $i^{th}$ 块选择 $j^{th}$ 的码率等级):
$$ \underset{X}{max} \sum^{m}_{t=1} Q_t $$
$Q_t$ 表示 $t^{th}$ 段的 QoE 分数,与以下几个方面有关:
VIewport Quality:
$$ Q^1_t = \sum^{N}_{i=1} \sum^{M}_{j=1} x_{i,j} \cdot p_i \cdot r_{i,j} $$
$p_i$ 表示 $i^{th}$ 分块的规范化观看概率; $r_{i,j}$ 记录块 $(i, j)$ 的码率;
Viewport Temporal Variation:
$$ Q^2_t = |Q^1_t - Q^{1}_{t-1}| $$
Viewport Spatial Variation:
$$ Q^3_t = \frac{1}{2} \sum^{N}_{i=1} \sum_{u \in U_i} p_i \cdot p_u \sum^{M}_{j=1} |x_{i,j} \cdot r_{i,j} - x_{u,j} \cdot r_{u,j}| $$
$U_i$ 表示 $i^{th}$ 个分块的 1 跳邻居中的 tile 索引[1];
Rebuffering:
$$ Q^4_t = max(\frac{\sum^{N}_{i=1} \sum^{M}_{j=1} x_{i,j} \cdot r_{i,j} \cdot T}{\xi_t} - b_{t-1}, 0) $$
$\xi_t$ 表示网络吞吐量; $b_{t-1}$ 表示播放器的缓冲区占用率;
最终的 QoE 可以由上面的指标定义:
$$ Q_t = Q^1_t - \eta_1 \cdot Q^2_t - \eta_2 \cdot Q^3_t - \eta_3 \cdot Q^4_t $$
$\eta_*$ 是可调节的参数,与不同的用户偏好对应。
Sequential RL-Based ABR
假设基于 tile 的全景推流 ABR 过程也是 MDP。
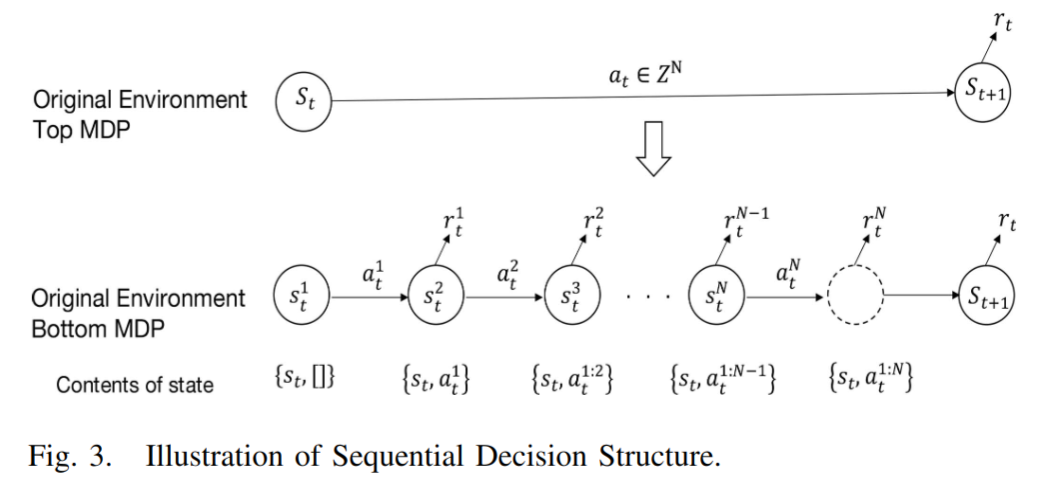
细节在360SRL中已经说明清楚。